

针对修改后的噪声进行微调,使稳定扩散能够轻松生成非常暗或非常亮的图像。
![图片[1]_训练Stable Diffusion模型之:Diffusion With Offset Noise](https://scdn.qpipi.com/2023/05/4c6224a8e2185846.webp)
使用偏移噪声之前(左)和之后(右)的稳定扩散
去噪扩散概率模型是一种相对较新的生成神经网络模型形式 – 从数据中学习的高维概率分布中生成样本的模型。同一类问题的其他方法包括生成对抗网络、规范化流和各种形式的自回归模型,这些模型一次或以块的形式对维度进行采样。这种建模的主要应用之一是图像合成,扩散模型最近在图像质量方面非常具有竞争力,特别是在在整个图像中产生全局一致的构图方面。
稳定扩散是一个预先训练的、公开可用的模型,可以使用这种技术产生一些惊人的结果。但是,它有一个有趣的限制,似乎大多被忽视了。如果你试图要求它生成应该特别暗或特别亮的图像,它几乎总是生成平均值相对接近 0.5 的图像(全黑图像为 0,全白图像为 1)。例如:
![图片[2]_训练Stable Diffusion模型之:Diffusion With Offset Noise](https://scdn.qpipi.com/2023/05/6e2607f3cf185930.webp)
左上:暴雨中的黑暗小巷(0.301);右上:白色背景上的单色线条艺术徽标 (0.709);左下:晴天白雪皑皑的滑雪场(0.641);右下:仅由手电筒照亮的城市广场(0.452)
在大多数情况下,这些图像仍然是合理的。但是,平均值在 0.5 左右的那种软约束会导致东西被冲刷掉,明亮的雾区域抵消其他黑暗区域,高频纹理(在徽标中)而不是空白区域,灰色背景而不是白色或黑色等。虽然其中一些可以通过后期处理手动校正或调整,但这里还有一个更大的潜在限制,因为场景的整体调色板可以与呈现和构图的其他方面相关联,而扩散模型无法像其他方法那样自由探索。
但它为什么要这样做呢?我只是在想象效果,这些结果是“正确的”吗?这仅仅是训练数据的问题,关于架构的问题,还是关于扩散模型的问题?(这是最后一次)。
不过,首先,为了确保我不只是在想象,我尝试针对单个纯黑色图像微调稳定扩散。一般来说,微调稳定扩散(SD)效果很好 – 有一种叫做Dreambooth的技术可以教SD新的,特定的概念,如特定的人的脸或特定的猫,几十张图像和几千个梯度更新足以让模型了解特定主题的样子。将其扩展到一万个步骤,它可以开始记住特定的图像。
但是当我对这个单一的纯黑色图像进行微调时,即使在 3000 步之后,我仍然得到这样的“纯黑色图像”结果:
![图片[3]_训练Stable Diffusion模型之:Diffusion With Offset Noise](https://scdn.qpipi.com/2023/05/84d1b9e30f190013.webp)
使用提示:“纯黑色图像”
因此,SD似乎不仅没有开箱即用地产生过暗或过亮图像的能力,而且它甚至无法学会这样做。
好吧,并非没有改变一件事。
要了解正在发生的事情,举例说明扩散模型正在学习逆转的确切内容会有所帮助。通常的扩散模型表述方式是作为特定前向随机过程的逆 – 重复添加少量“独立和相同分布”(iid)高斯噪声。也就是说,潜在空间中的每个像素在每一步都会接收自己的随机样本。扩散模型学会在执行了这些步骤之后获取图像,并找出沿着该轨迹返回原始图像的方向。给定这个可以“向真实图像倒退”的模型,您可以从纯噪声开始,然后逆转噪声过程以获得新颖的图像。
问题在于,在正向过程中,您永远不会完全擦除原始图像,因此反过来,从纯噪声开始的反向模型并不能完全恢复到图像的完整真实分布。相反,那些噪声最后破坏的东西反过来又被反向过程最弱地改变 – 这些东西是从用于开始处理的潜在噪声样本继承而来的。
乍一看可能并不明显,但如果您查看正向过程以及它如何破坏图像,较长的波长特征需要更长的时间才能破坏噪声:
https://www.youtube.com/embed/3C6yEYXDijM
![图片[4]_训练Stable Diffusion模型之:Diffusion With Offset Noise](https://scdn.qpipi.com/2023/05/8f187081af190105.webp)
这就是为什么例如使用相同的潜在噪声种子但不同的提示往往会在整体构图的层面上给出彼此相关的图像,而不是在单个纹理或小尺度模式的层面上。扩散过程不知道如何改变这些长波长特征。而波长最长的特征是图像整体的平均值,这也是潜噪噪声的独立样本之间变化最小的特征。
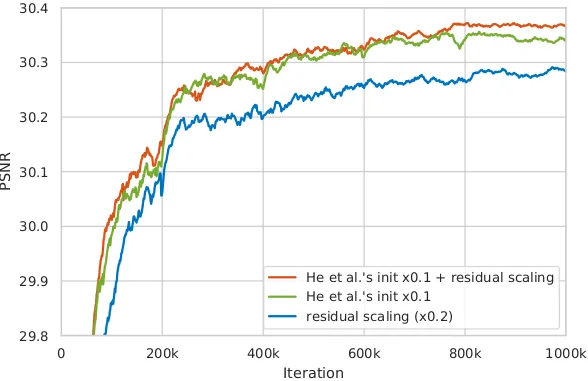
目标对象的维数越高,这个问题就越严重,因为一组独立噪声样本的标准差比例为 1/N。因此,如果您要生成 4D 矢量,这可能不是什么大问题 – 您只需要两倍的样本即可获得最低频率分量和最高频率分量。但在 512×512 分辨率的稳定扩散中,您将生成一个 3 x 64^2 = 12288 维的对象。因此,最长波长的变化比最短波长慢约100倍,这意味着当默认值约为50时,您需要考虑数百或数千个步骤才能捕获它(或者对于一些复杂的采样器,低至20)。
![图片[5]_训练Stable Diffusion模型之:Diffusion With Offset Noise](https://scdn.qpipi.com/2023/05/4ae1c2da54190129.webp)
似乎增加采样步骤的数量确实有助于SD制作更极端的图像,但我们可以做得更好一点,并制作一个直接的解决方案。
诀窍与我们教扩散模型反转的噪声结构有关。因为我们使用的是 iid 样本,所以我们有这个 1/N。但是,如果我们使用看起来像每个像素 iid 样本的噪声添加到整个图像上相同的单个 iid 样本中呢?
在代码术语中,当前训练循环使用的噪声如下所示:
noise = torch.randn_like(latents)
但相反,我可以使用这样的东西:
noise = torch.randn_like(latents) + 0.1 * torch.randn(latents.shape[0], latents.shape[1], 1, 1)
这将使模型学会自由更改组件的零频率,因为该组件现在的随机化速度比基分布快 ~10 倍(鉴于我有限的数据和训练时间,选择 0.1 对我来说效果很好 – 如果我让它太大,它往往会主导太多模型的现有行为, 但要小得多,我看不到改进)。
在40张手工标记的图像上用这样的噪声微调一千步左右,就足以显着改变稳定扩散的行为,而不会使它变得更糟。以下是本文中四个提示的结果,以便进行比较:
![图片[6]_训练Stable Diffusion模型之:Diffusion With Offset Noise](https://scdn.qpipi.com/2023/05/084738c553190315.webp)
右上:暴雨中的黑暗小巷(0.032);左上:白色背景上的单色线条艺术徽标 (0.974);左下:晴天白雪皑皑的滑雪场(0.858);右下:仅由手电筒照亮的城市广场。(0.031)
![图片[7]_训练Stable Diffusion模型之:Diffusion With Offset Noise](https://scdn.qpipi.com/2023/05/ad55d101c0190406.webp)
![图片[8]_训练Stable Diffusion模型之:Diffusion With Offset Noise](https://scdn.qpipi.com/2023/05/b817a0ff34190530.webp)
结论
有许多论文讨论了改变去噪扩散模型的噪声时间表,以及使用与高斯不同的分布来表示噪声,甚至完全消除噪声,而是使用其他破坏性操作,如模糊或掩蔽。然而,大部分重点似乎都集中在加速推理过程上——基本上能够使用更少的步骤。关于噪声(或图像销毁操作)的设计决策如何限制可以轻松合成的图像类型,似乎没有太多关注。但是,它与这些模型的美学和艺术用途非常相关。
对于正在深入研究定制这些模型并进行自己微调的个人艺术家来说,调整为将这种偏移噪声用于一个项目或另一个项目并不那么困难。如果您愿意,您可以使用我们的检查点(请在访问此文件之前阅读末尾的注释),就此而言。但是,通过对像这样的少量图像进行微调,结果永远不会像大型项目那样普遍或那么好。
因此,我想向参与训练这些大型模型的人提出一个请求:下次进行大跑步时,请在训练过程中加入一点这样的偏移噪声。它应该显着增加模型的表现范围,为徽标、抠图、自然明亮和黑暗场景、具有强烈色彩照明的场景等提供更好的效果。这是一个非常简单的技巧!
希望你喜欢使用这个AI模型,就像我们创造它一样!如果您有任何问题或建议,请在评论区告诉我们。
使用Qpipi读图提示功能,获取图片TAG Prompt提示
你想要什么SD绘画模型?请在Qpipi社区或者评论留言告诉我们!
🎨享受精美的AI绘图乐趣!






















暂无评论内容