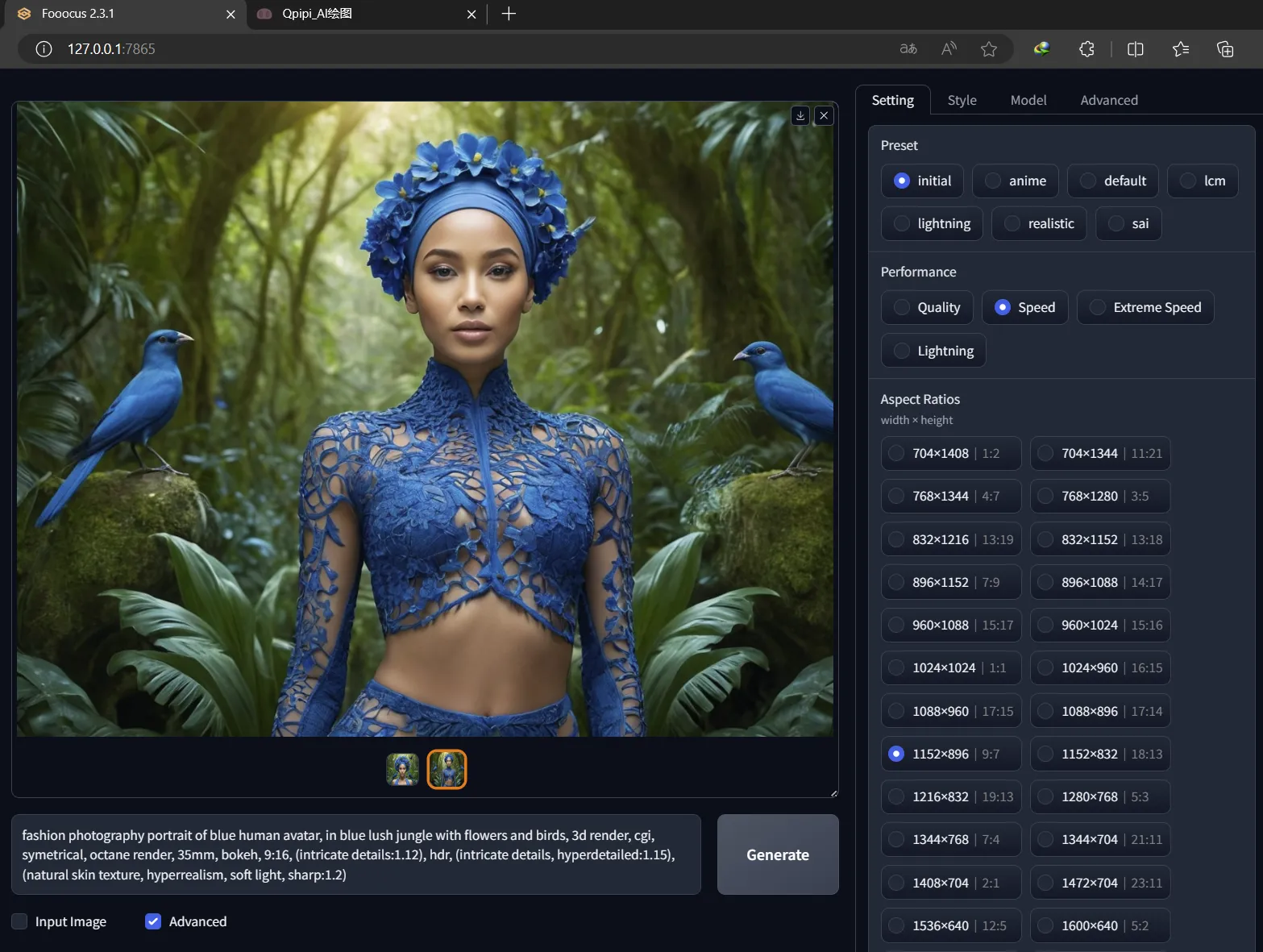
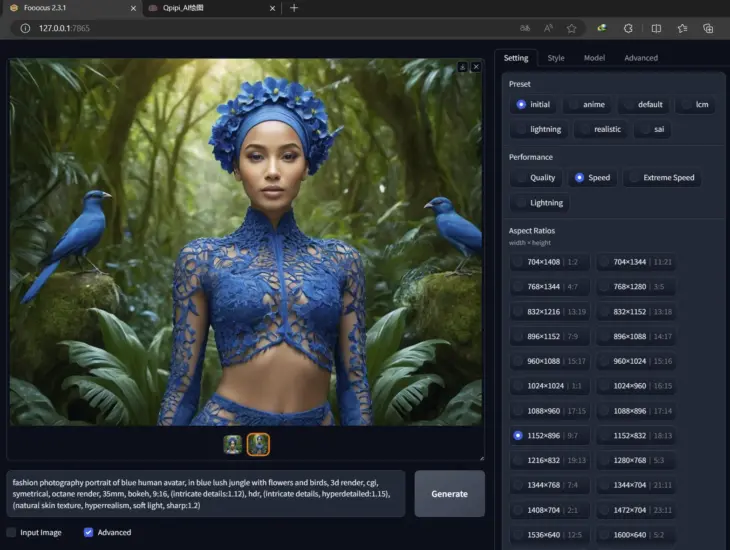


在经过一段时间使用后,Qpipi 很高兴再向各位推荐一款由 Github 大神 lllyasviel 制作的 Stable Diffusion 用户操作界面 Fooocus。
Fooocus 是一款SD AI图像生成软件(基于 Gradio),对于国内用户最大的好处是免去下载组件,和 ComfyUI 一样,即开即用非常省事。
![图片[1]_解压即用,新手友好!Fooocus 对 Stable Diffusion 和 Midjourney AI设计的重新思考](https://scdn.qpipi.com/2024/04/79aafbb53b20240420014008-1024x772.webp)
与ComfyUI的流程模块操作不同,Fooous更像是传统的WebUI操作,而且更简洁,对新手友好,并且功能和性能一点也不弱。
如果你不适应ComfyUI的操作,喜欢更简洁的步骤,那你一定要试试Fooocus。
![图片[2]_解压即用,新手友好!Fooocus 对 Stable Diffusion 和 Midjourney AI设计的重新思考](https://scdn.qpipi.com/2024/04/9c6d30c6e520240420014341-1024x769.webp)
Fooocus 是对 Stable Diffusion 和 Midjourney 设计的重新思考:
- 从 Stable Diffusion 学习,该软件是离线、开源和免费的。
- 从 Midjourney 中吸取教训,不需要手动调整,用户只需要专注于提示和图像即可。
Fooocus已经包含并自动化了许多内部优化和质量改进。用户可以忘记所有那些困难的技术参数,只享受人机交互,“探索新的思想媒介,扩展人类的想象力”。
Fooocus简化了安装。在按下“下载”和生成第一张图像之间,所需的鼠标点击次数严格限制在 3 次以下。最低 GPU 内存要求是 4GB (Nvidia)。
使用 Fooocus 和 Midjourney 一样简单(可能比 Midjourney 更容易),但这并不意味着我们缺乏功能。以下是详细信息。
| Midjourney | Fooocus |
|---|---|
| 高质量的文本到图像,无需太多的快速工程设计或参数调整。 (未知方法) | 高质量的文本到图像,无需太多的快速工程设计或参数调整。 (Fooocus 有一个基于离线 GPT-2 的提示处理引擎和许多采样改进,因此无论您的提示是短如“house in garden”还是长达 1000 字,结果总是很漂亮) |
| V1 V2 V3 V4 | 输入图像 ->高档或变化 ->变化(微妙)/变化(强烈) |
| U1 U2 U3 U4 | 输入图像 -> 高档或变体 ->高档 (1.5x) / 高档 (2x) |
| Inpaint / Up / Down / Left / Right (Pan) | 输入图像 -> Inpaint 或 Outpaint -> Inpaint / Up/Down / Left / Right (Fooocus使用自己的Inpaint算法和Inpaint模型,因此结果比所有其他使用标准SDXLinpaint方法/模型的软件更令人满意) |
| Image Prompt | 输入图像 -> 图像提示 (Fooocus使用自己的图像提示算法,因此结果质量和提示理解比所有其他使用标准SDXL方法(如标准IP适配器或修订版)的软件更令人满意) |
| –style | 高级 -> 风格 |
| –stylize | 高级 -> 高级 -> 指导 |
| –niji | 多个启动器:“run.bat”、“run_anime.bat”和“run_realistic.bat”。 Fooocus 在 Qpipi 上支持 SDXL 模型 |
| –quality | 先进>品质 |
| –repeat | 高级 -> 图像编号 |
| Multi Prompts (::) | 只需使用多行提示 |
| Prompt Weights | 您可以使用“I am (happy:1.5)”。 Fooocus 使用 A1111 的重新加权算法,因此如果用户直接从Qpipi复制提示,结果会优于 ComfyUI。(因为如果提示是在 ComfyUI 的重新加权中编写的,用户不太可能复制提示文本,因为他们更喜欢拖动文件) 要使用嵌入,您可以使用“(embedding:file_name:1.1)” |
| –no | 高级 -> 否定提示 |
| –ar | 高级 -> 纵横比 |
| InsightFace | 输入图像 -> 图像提示 -> 高级 -> FaceSwap |
| Describe | 输入图像 -> 描述 |
我们还从LeonardoAI最好的部分借鉴了一些东西:
| LeonardoAI | Fooocus |
|---|---|
| 提示魔术 | 高级 -> 样式 -> Fooocus V2 |
| 高级采样器参数(如对比度/锐度/等) | 高级 -> 高级 -> 采样锐度 / 等 |
| 用户友好的 ControlNets | 输入图像 -> 图像提示 -> 高级 |
Fooocus 还为高级用户开发了许多“仅限 fooocus”的功能,以获得完美的结果。
下载
Windows
海外下载地址:Github Fooocus
Qpipi国内下载地址( windows/linux 基础版 和 带模型版):
下载文件后,请解压缩,然后运行“run.bat”。
注意:
run_anime.bat run_realistic.bat 需要下载模型后才能运行,Qpipi带模型版一般不需要用这两者。如果有需要可以在以下链接下载:
run_anime.bat 模型下载页(选版本v1.00):https://www.qpipi.com/40956/
run_realistic.bat 模型下载页(选版本 v2.0):https://www.qpipi.com/47921/
run.bat 模型下载页(选版本 v8.0):https://www.qpipi.com/35784/
国内 Fooocus 最新版Qpipi下载页面:https://www.qpipi.com/47984/
如有安装使用问题,请在Qpipi.com社区留言。
不带模型版首次启动软件时,它会自动下载模型(国内下载不了):
- 它会在给定不同预设的情况下将默认模型下载到文件夹“Fooocus\models\checkpoints”。如果您不想自动下载,可以提前下载它们。
- 请注意,如果您使用 inpaint,在您第一次绘制图像时,它将下载 Fooocus 自己的 inpaint 控制模型,作为文件“Fooocus\models\inpaint\inpaint_v26.fooocus.patch”(此文件的大小为 1.28GB)。
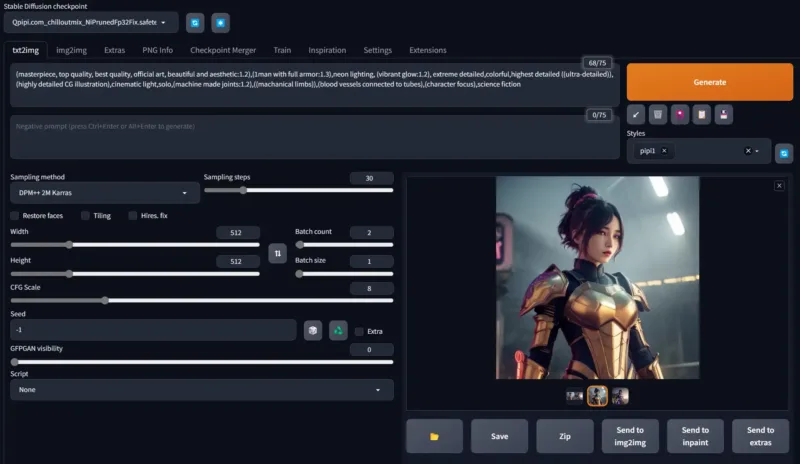
国内Qpipi下载(不用 inpaint 可以不下载):
![图片[3]_解压即用,新手友好!Fooocus 对 Stable Diffusion 和 Midjourney AI设计的重新思考](https://scdn.qpipi.com/2024/04/89230b75f120240420103933.webp)
在 Fooocus 2.1.60 之后,您还将拥有 和 .它们是不同的模型预设(需要不同的模型,但它们会自动下载)。查看此处了解更多详情。
run_anime.bat
run_realistic.bat在Fooocus 2.3.0之后,您还可以直接在浏览器中切换预设。如果要更改默认行为,请记住添加以下参数:
- 用于禁用浏览器中的预设选择。
--disable-preset-selection - 用于在预设开关上下载缺失的模型。默认为回退到相应预设中定义的,另请参阅终端输出。
--always-download-new-modelprevious_default_models
![图片[4]_解压即用,新手友好!Fooocus 对 Stable Diffusion 和 Midjourney AI设计的重新思考](https://scdn.qpipi.com/2024/04/ea70038c5520240420104013.webp)
如果您已经有这些文件,则可以将它们复制到上述位置以加快安装速度(例图中的三个模型一般有其中一个即可!无需全部下载)。
Qpipi下载 sd_xl_base_1.0_0.9vae.safetensors 和 sd_xl_refiner_1.0_0.9vae.safetensors 模型:
请注意,如果您看到“MetadataIncompleteBuffer”或“PytorchStreamReader”,则您的模型文件已损坏。请重新下载模型。
请注意,Fooocus 最低要求是 4GB Nvidia GPU 内存 (4GB VRAM) 和 8GB 系统内存 (8GB RAM)。这需要使用 Microsoft 的虚拟内存交换技术,在大多数情况下,Windows 安装会自动启用该技术,因此您通常不需要对此执行任何操作。但是,如果您不确定,或者您手动关闭了它(真的有人会这样做吗?)
推荐的负面提示嵌入(版本 v3.1、hk1 选一即可):
![图片[5]_解压即用,新手友好!Fooocus 对 Stable Diffusion 和 Midjourney AI设计的重新思考](https://scdn.qpipi.com/2024/04/6534e62a4920240420110518.webp)
下载:
Colab
在 Colab 中,您可以将最后一行修改为 或 或 Fooocus Default/Anime/Realistic Edition。
.\python_embeded\python.exe entry_with_update.py --directml --preset anime
.\python_embeded\python.exe entry_with_update.py --directml --preset realistic您还可以在 UI 中更改预设。请注意,这可能会导致 60 秒后超时。如果是这种情况,请等到下载完成,将预设更改为初始并返回您选择的预设或重新加载页面。
请注意,此 Colab 默认情况下会禁用精简程序,因为 Colab free 的资源相对有限(并且一些“大”功能(如图像提示)可能会导致免费层 Colab 断开连接)。我们确保基本的文本到图像始终适用于免费层 Colab。
使用将资源分配从 RAM 转移到 VRAM,并在默认 T4 实例上实现性能、灵活性和稳定性之间的整体最佳平衡。请在此处找到更多信息。--always-high-vram
感谢 camenduru 的模板!
Linux(使用 Anaconda)
如果你想使用 Anaconda/Miniconda,你可以
git clone https://github.com/lllyasviel/Fooocus.git
cd Fooocus
conda env create -f environment.yaml
conda activate fooocus
pip install -r requirements_versions.txt
然后下载模型:将默认模型下载到文件夹“Fooocus\models\checkpoints”。或者让 Fooocus 使用启动器自动下载模型:
conda activate fooocus
python entry_with_update.py
或者,如果要打开远程端口,请使用
conda activate fooocus
python entry_with_update.py --listen
用于 Fooocus Anime/Realistic Edition。
run_anime.bat run_realistic.bat
python entry_with_update.py --preset realisticLinux(使用 Python Venv)
您的 Linux 需要安装 Python 3.10,假设您的 Python 可以在 venv 系统正常工作的情况下使用命令 python3 调用;您可以
git clone https://github.com/lllyasviel/Fooocus.git
cd Fooocus
python3 -m venv fooocus_env
source fooocus_env/bin/activate
pip install -r requirements_versions.txt
有关模型下载,请参阅上述部分。您可以通过以下方式启动软件:
source fooocus_env/bin/activate
python entry_with_update.py
或者,如果要打开远程端口,请使用
source fooocus_env/bin/activate
python entry_with_update.py --listen
用于 Fooocus Anime/Realistic Edition。
python entry_with_update.py --preset anime
python entry_with_update.py --preset realisticLinux(使用本机系统 Python)
如果你知道你在做什么,并且你的 Linux 已经安装了 Python 3.10,并且你的 Python 可以使用命令 python3 调用(Pip 和 pip3),你可以
git clone https://github.com/lllyasviel/Fooocus.git
cd Fooocus
pip3 install -r requirements_versions.txt
有关模型下载,请参阅上述部分。您可以通过以下方式启动软件:
python3 entry_with_update.py
或者,如果要打开远程端口,请使用
python3 entry_with_update.py --listen
用于 Fooocus Anime/Realistic Edition。
python entry_with_update.py --preset anime
python entry_with_update.py --preset realisticLinux(AMD GPU)
请注意,不同平台的最低要求是不同的。
与上述说明相同。您需要将火炬更改为 AMD 版本
pip uninstall torch torchvision torchaudio torchtext functorch xformers
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.6
然而,AMD没有经过深入测试。AMD支持处于测试阶段。
用于 Fooocus Anime/Realistic Edition。
python entry_with_update.py --preset anime
python entry_with_update.py --preset realisticWindows(AMD GPU)
请注意,不同平台的最低要求是不同的。
与 Windows 相同。下载软件并编辑内容:run.bat
.\python_embeded\python.exe -m pip uninstall torch torchvision torchaudio torchtext functorch xformers -y
.\python_embeded\python.exe -m pip install torch-directml
.\python_embeded\python.exe -s Fooocus\entry_with_update.py --directml
pause
然后运行 .run.bat
然而,AMD没有经过深入测试。AMD支持处于测试阶段。
对于 AMD,请使用 或 用于 Fooocus Anime/Realistic Edition。
.\python_embeded\python.exe entry_with_update.py --directml --preset anime
.\python_embeded\python.exe entry_with_update.py --directml --preset realistic苹果电脑
请注意,不同平台的最低要求是不同的。
Mac 没有经过严格测试。以下是使用 Mac 的非官方指南。你可以在这里讨论问题。
您可以在装有macOS“Catalina”或更新版本的Apple Mac芯片(M1或M2)上安装Fooocus。Fooocus 通过 PyTorch MPS 设备加速在 Apple 芯片计算机上运行。Mac Silicon 电脑没有配备专用显卡,与配备专用显卡的电脑相比,图像处理时间明显更长。
- 每晚安装 conda 包管理器和 pytorch。阅读 Mac 上的加速 PyTorch 培训 Apple 开发人员指南,了解相关说明。确保 pytorch 识别您的 MPS 设备。
- 打开 macOS 终端应用程序并使用 .
git clone https://github.com/lllyasviel/Fooocus.git - 切换到新的 Fooocus 目录。
cd Fooocus - 创建新的 conda 环境 。
conda env create -f environment.yaml - 激活新的 conda 环境 。
conda activate fooocus - 安装 Fooocus, 所需的软件包。
pip install -r requirements_versions.txt - 通过运行 .(某些 Mac M2 用户可能需要加快机种加载/卸载速度。首次运行Fooocus时,它将自动下载Stable Diffusion SDXL模型,并且需要大量时间,具体取决于您的互联网连接。
python entry_with_update.pypython entry_with_update.py --disable-offload-from-vram
用于 Fooocus Anime/Realistic Edition。
python entry_with_update.py --preset anime
python entry_with_update.py --preset realistic最低要求
以下是在本地运行Fooocus的最低要求。如果您的设备功能低于此规格,您可能无法在本地使用 Fooocus。(无论如何,如果您的设备功能较低但 Fooocus 仍然有效,请告诉我们。
| 操作系统 | 显卡 | 最小 GPU 内存 | 最小系统内存 | 虚拟内存 | 注意 |
|---|---|---|---|---|---|
| Windows/Linux系统 | 英伟达RTX 4XXX | 4GB | 8GB | 必需 | 很快 |
| Windows/Linux系统 | 英伟达RTX 3XXX | 4GB | 8GB | 必需 | 通常比 RTX 2XXX 快 |
| Windows/Linux系统 | 英伟达RTX 2XXX | 4GB | 8GB | 必需 | 通常比 GTX 1XXX 快 |
| Windows/Linux系统 | 英伟达GTX 1XXX | 8GB (* 6GB 不确定) | 8GB | 必需 | 仅比 CPU 快一点 |
| Windows/Linux系统 | 英伟达GTX 9XX | 8GB | 8GB | 必需 | 比 CPU 更快或更慢 |
| Windows/Linux系统 | 英伟达GTX < 9XX | 不支持 | / | / | / |
| Windows | AMD GPU处理器 | 8GB(2023 年 12 月 30 日更新) | 8千兆字节 | 必需 | 通过 DirectML(* ROCm 处于暂停状态),比 Nvidia RTX 3XXX 慢约 3 倍 |
| Linux操作系统 | AMD GPU处理器 | 8千兆字节 | 8千兆字节 | 必需 | 通过 ROCm,比 Nvidia RTX 3XXX 慢约 1.5 倍 |
| 苹果电脑 | M1/M2 MPS型 | 共享 | 共享 | 共享 | 比 Nvidia RTX 3XXX 慢约 9 倍 |
| Windows/Linux/Mac | 仅使用 CPU | 0GB | 32千兆字节 | 必需 | 比 Nvidia RTX 慢约 17 倍 3XXX |
* AMD GPU ROCm(暂停):AMD 仍在努力在 Windows 上支持 ROCm。
* Nvidia GTX 1XXX 6GB 不确定:有些人报告在 GTX 10XX 上成功了 6GB,但也有人报告了失败案例。(注:Qpipi测试可以,系统内存需要至少16G)
请注意,Fooocus 仅适用于极高质量的图像生成。我们不会支持较小的模型,以降低要求并牺牲结果质量。
默认模型
给定不同的目标,Fooocus 的默认模型和配置是不同的:
| 任务 | Windows | Linux 参数 | 主要型号 | Refiner | 配置 |
|---|---|---|---|---|---|
| 常规 | run.bat | juggernautXL_v8Rundiffusion | 未使用 | 这里 | |
| 现实 | run_realistic.bat | –preset realistic | realisticStockPhoto_v20 | 未使用 | 这里 |
| 动漫 | run_anime.bat | –preset anime | animaPencilXL_v100 | 未使用 | 这里 |
请注意,下载是自动的 – 如果互联网连接正常(海外用户可以),则无需执行任何操作。但是,如果您(或从其他地方移动它们)有自己的准备,您可以手动下载它们(国内用户手动)。
UI 访问和身份验证
除了在 localhost 上运行之外,Fooocus 还可以通过两种方式公开其 UI:
- 本地 UI 侦听器:使用(指定端口,例如 with )。
--listen--port 8888 - API 访问:use(在 中注册端点)。
--share.gradio.live
默认情况下,这两种方式的访问都是未经身份验证的。您可以通过创建在主目录中调用的文件来添加基本身份验证,该文件包含带有键和 (请参阅auth-example.json中的示例) 的 JSON 对象列表。auth.json user pass
“隐藏”技巧列表
以下内容已经在软件中,用户无需对这些内容执行任何操作。
- 基于 GPT2 的提示扩展为动态样式“Fooocus V2”。 (类似于 Midjourney 的隐藏预处理和“原始”模式,或 LeonardoAI 的 Prompt Magic)。
- 在一个 k-sampler 内进行原生精炼器交换。优点是精简器模型现在可以重用从 k 采样收集的基础模型的动量(或 ODE 的历史参数),以实现更连贯的采样。在 Automatic1111 的高分辨率修复和 ComfyUI 的节点系统中,基本模型和精简器使用两个独立的 k 采样器,这意味着动量在很大程度上被浪费了,采样连续性被破坏了。Fooocus使用其先进的k扩散采样技术,确保在精炼机设置中实现无缝、原生和连续的交换。(8 月 13 日更新:实际上,我几天前和 Automatic1111 讨论过这个问题,似乎“单个 k-sampler 中的原生精简器交换”被合并到 webui 的 dev 分支中。太棒了!
- 负面的ADM指导。由于 XL Base 的最高分辨率级别没有交叉注意力,因此 XL 最高分辨率级别的正信号和负信号在 CFG 采样期间无法获得足够的对比度,导致结果在某些情况下看起来有点可塑性或过于平滑。幸运的是,由于 XL 的最高分辨率级别仍然以图像纵横比 (ADM) 为条件,我们可以修改正/负侧的 adm,以弥补最高分辨率级别下 CFG 对比度的不足。(8 月 16 日更新,IOS App Draw Things 将支持负面 ADM 指导。太棒了!
- 我们实施了 prompt expansion as a dynamic style “Fooocus V2”. 第 5.1 节的精心调整变体。重量设置为非常低,但这是 Fooocus 的最终保证,以确保 XL 永远不会产生过于光滑或塑料的外观(此处为示例)。这几乎可以消除 XL 偶尔仍会产生过于平滑结果的所有情况,即使有负面的 ADM 指导也是如此。(2023 年 8 月 18 日更新,SAG 的高斯核改为各向异性核,以更好地保留结构,减少伪影。
- 我们对样式模板进行了一些修改,并添加了“cinematic-default”。
- 我们测试了“sd_xl_offset_example-lora_1.0.safetensors”,似乎当 lora 权重低于 0.5 时,结果总是优于没有 lora 的 XL。
- 采样器的参数经过仔细调整。
- 由于 XL 使用位置编码进行生成分辨率,因此由多个固定分辨率生成的图像看起来比来自任意分辨率的图像更好(因为位置编码不太擅长处理训练期间看不见的整数)。这表明 UI 中的分辨率可能是硬编码的,以获得最佳效果。
- 对于两个不同的文本编码器,单独的提示似乎没有必要。基本模型和精简程序的单独提示可能有效,但效果是随机的,我们避免实现这一点。
- DPM 系列似乎非常适合 XL,因为 XL 有时会生成过于平滑的纹理,但 DPM 系列有时会在纹理中生成过于密集的细节。它们的联合效果看起来是中性的,对人类的感知很有吸引力。
- 一个精心设计的系统,用于平衡多种风格以及快速扩展。
- 使用 automatic1111 的方法规范化提示强调。当用户直接从 Qpipi 复制提示时,这显着改善了结果。
- 炼油厂的联合交换系统现在也以无缝方式支持img2img和upscale。
- 当 CFG 大于 10 时,CFG 量表和 TSNR 校正(针对 SDXL 进行了调整)。
定制
首次运行 Fooocus 后,将在 处生成一个配置文件。可以编辑此文件以更改模型路径或默认参数。Fooocus\config.txt
例如,编辑后(此文件将在首次启动后生成)可能如下所示:Fooocus\config.txt
{
"path_checkpoints": "D:\\Fooocus\\models\\checkpoints",
"path_loras": "D:\\Fooocus\\models\\loras",
"path_embeddings": "D:\\Fooocus\\models\\embeddings",
"path_vae_approx": "D:\\Fooocus\\models\\vae_approx",
"path_upscale_models": "D:\\Fooocus\\models\\upscale_models",
"path_inpaint": "D:\\Fooocus\\models\\inpaint",
"path_controlnet": "D:\\Fooocus\\models\\controlnet",
"path_clip_vision": "D:\\Fooocus\\models\\clip_vision",
"path_fooocus_expansion": "D:\\Fooocus\\models\\prompt_expansion\\fooocus_expansion",
"path_outputs": "D:\\Fooocus\\outputs",
"default_model": "realisticStockPhoto_v10.safetensors",
"default_refiner": "",
"default_loras": [["lora_filename_1.safetensors", 0.5], ["lora_filename_2.safetensors", 0.5]],
"default_cfg_scale": 3.0,
"default_sampler": "dpmpp_2m",
"default_scheduler": "karras",
"default_negative_prompt": "low quality",
"default_positive_prompt": "",
"default_styles": [
"Fooocus V2",
"Fooocus Photograph",
"Fooocus Negative"
]
}还有许多其他键、格式和示例(此文件将在首次启动后生成)。Fooocus\config_modification_tutorial.txt
在真正更改配置之前,请三思而后行。如果您发现自己破坏了东西,只需删除 .Fooocus 将恢复为默认值。Fooocus\config.txt
更安全的方法是尝试“run_anime.bat”或“run_realistic.bat”——它们应该已经足以胜任不同的任务。
所有 CMD 标志
entry_with_update.py [-h] [--listen [IP]] [--port PORT]
[--disable-header-check [ORIGIN]]
[--web-upload-size WEB_UPLOAD_SIZE]
[--external-working-path PATH [PATH ...]]
[--output-path OUTPUT_PATH] [--temp-path TEMP_PATH]
[--cache-path CACHE_PATH] [--in-browser]
[--disable-in-browser] [--gpu-device-id DEVICE_ID]
[--async-cuda-allocation | --disable-async-cuda-allocation]
[--disable-attention-upcast] [--all-in-fp32 | --all-in-fp16]
[--unet-in-bf16 | --unet-in-fp16 | --unet-in-fp8-e4m3fn | --unet-in-fp8-e5m2]
[--vae-in-fp16 | --vae-in-fp32 | --vae-in-bf16]
[--clip-in-fp8-e4m3fn | --clip-in-fp8-e5m2 | --clip-in-fp16 | --clip-in-fp32]
[--directml [DIRECTML_DEVICE]] [--disable-ipex-hijack]
[--preview-option [none,auto,fast,taesd]]
[--attention-split | --attention-quad | --attention-pytorch]
[--disable-xformers]
[--always-gpu | --always-high-vram | --always-normal-vram |
--always-low-vram | --always-no-vram | --always-cpu [CPU_NUM_THREADS]]
[--always-offload-from-vram] [--disable-server-log]
[--debug-mode] [--is-windows-embedded-python]
[--disable-server-info] [--share] [--preset PRESET]
[--language LANGUAGE] [--disable-offload-from-vram]
[--theme THEME] [--disable-image-log]高级功能
AI绘图常用工具
希望你喜欢使用这个AI模型,就像我们创造它一样!如果您有任何问题或建议,请在评论区告诉我们。
使用Qpipi读图提示功能,获取图片TAG Prompt提示
你想要什么SD绘画模型?请在Qpipi社区或者评论留言告诉我们!
🎨享受精美的AI绘图乐趣!






















- 最新
- 最热
只看作者