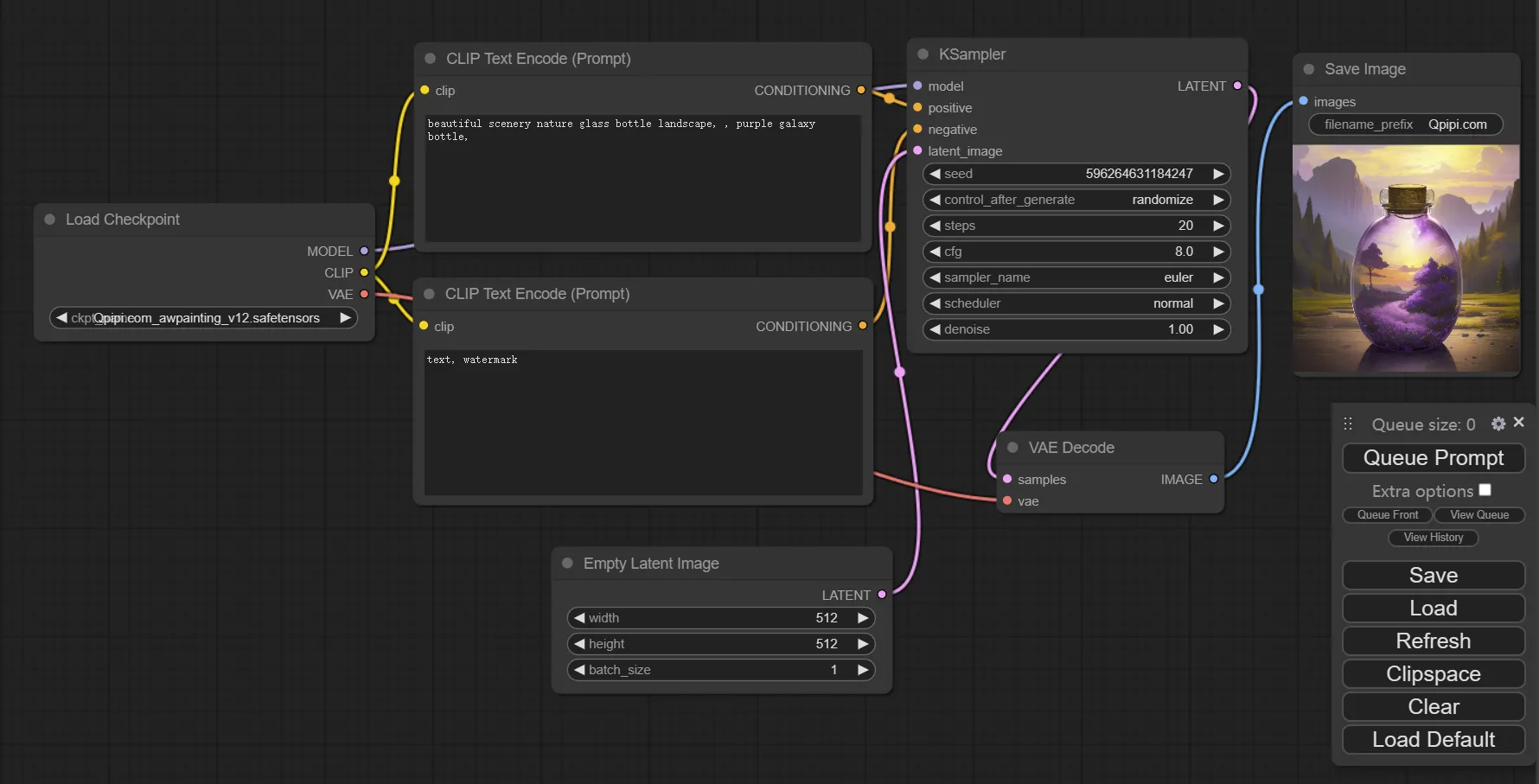


一直以来,Stable Diffusion 的各种UI的安装困扰了不少国内网友(因为各种墙),有没有一个开箱即用、操作简单、功能强大的Stable Diffusion UI呢?现在,由 Github 大神 comfyanonymous 开发的 ComfyUI 为我们解决了这一问题!
![图片[1]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321145113-1024x399.webp)
ComfyUI 基于 Stable Diffusion 底层的图形、节点、流程图、操作执行界面,对新手特别友好,解压后可以立即使用,无需在线下载组件。(绘图模型CP可以在Qpipi的大模型CP区或其它网站自行下载)
目前ComfyUI的Windows版本只支持Nvidia显卡加速,AMD/Intel显卡暂时只能使用Linux版本或者CPU运算(下文介绍如何安装)。
ComfyUI支持SD1.x、2.x和SDXL各类大模型CP,也支持Loras、VAE、TI、ESRGAN等模型(详见后文),可以满足大多数人的AI制图需要了。
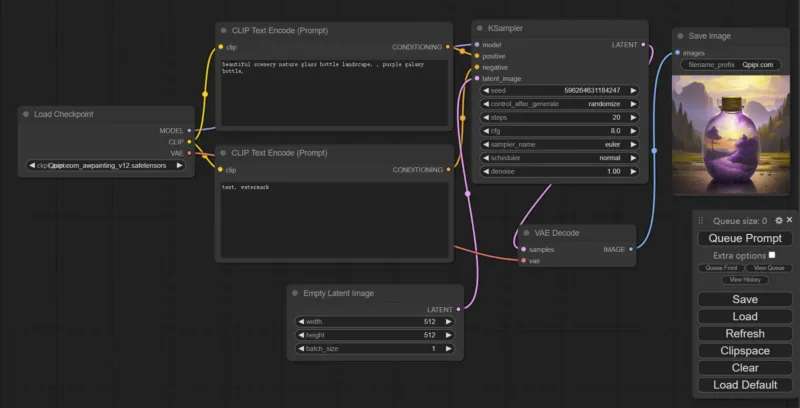
![图片[2]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321140829-1024x453.webp)
ComfyUI的性能优化出众,老爷机GTX970/4G显卡默认设置512x512px首次出图仅需24秒,之后降至20秒内,1024x1024px也能直出。
简单介绍完,后面有更详细的,感兴趣的可以先开始下载啦!
下载地址
Github下载:Releases · comfyanonymous/ComfyUI (github.com)
因为众所周知的原因,国内上Github不稳定,我提供一个ComfyUI原版的国内下载备用。
ComfyUI Windows v2.2 cu121
简易安装和启动
1、下载后使用Winzip/Winrar/7-zip之类的压缩软件,解压至一个空间够大的硬盘上(例如d:\ComfyUI)。然后进入ComfyUI目录,在第一次执行前做好以下准备。
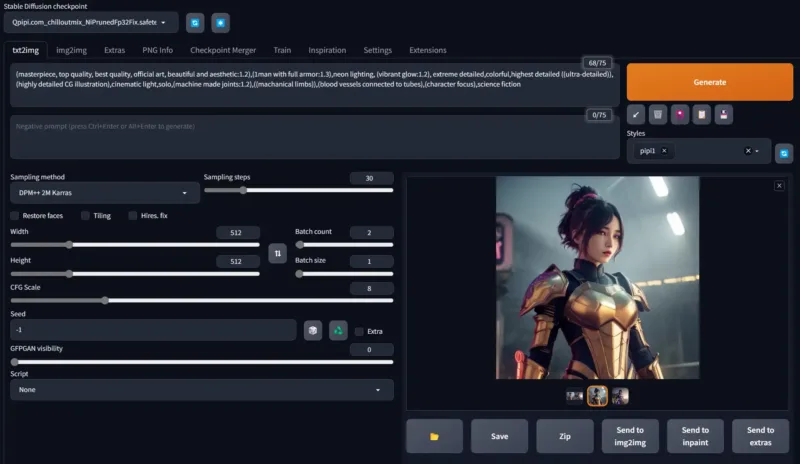
4、完成后可以看到界面
![图片[3]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321140517-1024x475.webp)
5、选择一个大模型CP,点 Queue Prompt 绘制你的第一幅大作吧!(进阶使用在后文中介绍)
ComfyUI 介绍
强大、模块化最稳定的 Stable Diffusion GUI 和后端
ComfyUI特征
- 节点/图形/流程图接口,无需编写任何代码即可进行实验和创建复杂的 Stable Diffusion 工作流程。
- 完全支持SD1.x、SD2.x、SDXL、Stable Video Diffusion和Stable Cascade
- 异步队列系统
- 许多优化:仅重新执行工作流中在执行之间更改的部分。
- 命令行选项:使其在 vram 小于 3GB 的 GPU 上工作(在低 vram 的 GPU 上自动启用)
--lowvram - 即使您没有具有以下功能的 GPU 也能正常工作:(慢)
--cpu - 可以加载 ckpt、safetensor 和 diffusers 模型/检查点。独立的 VAE 和 CLIP 型号。
- 嵌入/文本反转
- Loras(Lycoris、locon 和 loha)
- Hypernetworks
- 从生成的 PNG 文件加载完整的工作流(带种子)。
- 将工作流保存/加载为 Json 文件。
- 节点接口可用于创建复杂的工作流程,例如用于 Hires fix 或更高级的工作流程。
- 区域构成
- 使用常规模型和修复模型进行修复。
- ControlNet 和 T2I 适配器
- 高档型号(ESRGAN、ESRGAN 变体、SwinIR、Swin2SR 等)
- unCLIP Models
- GLIGEN
- 模型合并
- LCM 模型和 Loras
- SDXL Turbo
- 使用 TAESD 进行潜在预览
- 启动速度非常快。
- 完全离线工作:永远不会下载任何内容。
- 配置文件,用于设置模型的搜索路径。
ComfyUI快捷键
| Keybind | Explanation |
|---|---|
| Ctrl + Enter | Queue up current graph for generation |
| Ctrl + Shift + Enter | Queue up current graph as first for generation |
| Ctrl + Z/Ctrl + Y | Undo/Redo |
| Ctrl + S | Save workflow |
| Ctrl + O | Load workflow |
| Ctrl + A | Select all nodes |
| Alt + C | Collapse/uncollapse selected nodes |
| Ctrl + M | Mute/unmute selected nodes |
| Ctrl + B | Bypass selected nodes (acts like the node was removed from the graph and the wires reconnected through) |
| Delete/Backspace | Delete selected nodes |
| Ctrl + Delete/Backspace | Delete the current graph |
| Space | Move the canvas around when held and moving the cursor |
| Ctrl/Shift + Click | Add clicked node to selection |
| Ctrl + C/Ctrl + V | Copy and paste selected nodes (without maintaining connections to outputs of unselected nodes) |
| Ctrl + C/Ctrl + Shift + V | Copy and paste selected nodes (maintaining connections from outputs of unselected nodes to inputs of pasted nodes) |
| Shift + Drag | Move multiple selected nodes at the same time |
| Ctrl + D | Load default graph |
| Q | Toggle visibility of the queue |
| H | Toggle visibility of history |
| R | Refresh graph |
| Double-Click LMB | Open node quick search palette |
Ctrl can also be replaced with Cmd instead for macOS users
| 键绑定 | 解释 |
|---|---|
| Ctrl + Enter | 将当前图形排队以供生成 |
| Ctrl + Shift + Enter | 将当前图形排成第一个队列以供生成 |
| Ctrl + Z/Ctrl + Y | 撤消/重做 |
| Ctrl + S | 保存工作流 |
| Ctrl + O | 加载工作流 |
| Ctrl + 一个 | 选择所有节点 |
| Alt + C | 折叠/取消折叠所选节点 |
| Ctrl + M | 静音/取消静音所选节点 |
| Ctrl + B | 绕过选定的节点(就像从图形中删除节点并重新连接电线一样) |
| Delete/Backspace | 删除所选节点 |
| Ctrl + Delete/Backspace | 删除当前图形 |
| Space | 按住画布并移动光标时四处移动画布 |
| Ctrl/Shift + 单击 | 将单击的节点添加到所选内容 |
| Ctrl + C/Ctrl + V | 复制和粘贴选定的节点(不维护与未选定节点输出的连接) |
| Ctrl + C/Ctrl + Shift + V | 复制和粘贴选定的节点(维护从未选定节点的输出到粘贴节点的输入的连接) |
| Shift + 拖动 | 同时移动多个选定节点 |
| Ctrl + D | 加载默认图形 |
| Q | 切换队列的可见性 |
| H | 切换历史记录的可见性 |
| R | 刷新图表 |
| 双击 LMB | 打开节点快速搜索面板 |
对于macOS用户,Ctrl也可以替换为Cmd
2 Pass Txt2Img (Hires fix)
这些示例演示了如何实现“Hires Fix”功能。
Hires Fix只是以较低的分辨率创建图像,放大它,然后通过 img2img 发送它。请注意,在 ComfyUI 中,txt2img 和 img2img 是同一个节点。Txt2Img 是通过将空图像传递给具有最大去噪的采样器节点来实现的。
以下是 ComfyUI 中的一个简单的工作流程,用于通过基本的潜在升级来做到这一点:
![图片[4]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321162306-1024x409.webp)
Non latent Upscaling
下面是一个示例,说明如何将 esrgan 升频器用于升频步骤。由于 ESRGAN 在像素空间中运行,因此图像必须在放大后转换为像素空间并返回潜在空间。
![图片[5]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321162451-1024x363.webp)
更多示例
下面是一个更复杂的 2 通道工作流程的示例,此图像首先使用 WD1.5 beta 3 illusion 模型生成,潜伏放大,然后使用 cardosAnime_v10 完成第二次传递:
![图片[6]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321162504-1024x576.webp)
Img2Img 示例
这些是演示如何执行 img2img 的示例。您可以在 ComfyUI 中加载这些图像以获得完整的工作流程。
Img2Img 的工作原理是加载像这个示例图像这样的图像,用 VAE 将其转换为潜在空间,然后以低于 1.0 的去噪对其进行采样。降噪控制添加到图像中的噪点量。降噪越低,添加的噪点就越少,图像变化也就越小。
输入图像应放在输入(input)文件夹中。
![图片[7]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321161437-1024x550.webp)
这就是一个简单的 img2img 工作流程的样子,它与默认的 txt2img 工作流程相同,但降噪设置为 0.87,并且加载的图像被传递到采样器而不是空图像。
LoRAs使用
这些是演示如何使用 Loras 的示例。所有 LoRA 类型:Lycoris、loha、lokr、locon 等……以这种方式使用。
您可以在 ComfyUI 中加载这些图像以获得完整的工作流程。
![图片[8]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321151231-1024x375.webp)
您可以通过链接多个 LoraLoader 节点来应用多个 Loras,如下所示:
![图片[9]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321151257-1024x352.webp)
Textual Inversion/Embeddings
以下是如何使用文本反转/嵌入的示例。
![图片[10]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321163136-1024x403.webp)
要使用嵌入,请将文件放在 models/embeddings 文件夹中,然后在提示中使用它,就像我在上图中使用 SDA768.pt 嵌入一样。
请注意,您可以省略文件扩展名,因此这两个是等效的:
embedding:SDA768.pt
embedding:SDA768
您还可以像在提示中设置常规单词一样设置嵌入的强度:
(embedding:SDA768:1.2)
嵌入基本上是自定义单词,因此将它们放在文本提示中的位置很重要。
例如,如果你嵌入了一只猫:
red embedding:cat
这可能会给你一只红猫。
ESRGAN 等高档模型
以下是如何使用 ESRGAN 等高档模型的示例。将它们放在 models/upscale_models 文件夹中,然后使用 UpscaleModelLoader 节点来加载它们,并使用 ImageUpscaleWithModel 节点来使用它们。
下面是一个示例:
![图片[11]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321152301-1024x380.webp)
Hypernetwork
Hypernetwork是应用于主 MODEL 的补丁,因此要使用它们,请将它们放在 models/hypernetworks 目录中,并使用 Hypernetwork Loader 节点,如下所示:
![图片[12]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321152532-1024x410.webp)
您可以通过按顺序链接多个 Hypernetwork Loader 节点来应用多个Hypernetwork。
ControlNet/T2I
请注意,在这些示例中,原始映像直接传递到 ControlNet/T2I 适配器。
如果您想要获得良好的结果,每个 ControlNet/T2I 适配器都需要传递给它的图像采用特定格式,如深度图、精明图等,具体取决于特定模型。
ControlNetApply 节点不会为您将常规图像转换为深度贴图、精简贴图等。
ControlNet 模型文件位于 ComfyUI/models/controlnet 目录中。
下面是一个如何使用控制网的简单示例,此示例使用 scribble controlnet 和 AnythingV3 模型。您可以在 ComfyUI 中加载此图像以获取完整的工作流程。
![图片[13]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321155649-1024x447.webp)
以下是我用于此工作流的输入图像:
![图片[14]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321155612.webp)
T2I-Adapter vs ControlNets
T2I-Adapters 比 ControlNet 效率高得多,因此我强烈推荐它们。ControlNets将大大降低速度,而T2I适配器对速度的负面影响几乎为零。
在 ControlNets 中,ControlNet 模型每次迭代运行一次。对于 T2I-Adapter,该模型总共运行一次。
T2I-Adapters的使用方式与ComfyUI中的ControlNets相同:使用ControlNetLoader节点。
这是将在此示例源中使用的输入图像:
![图片[15]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321155720.webp)
以下是使用深度 T2I 适配器的方法:
![图片[16]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321155735-1024x467.webp)
以下是使用深度 Controlnet 的方法。请注意,此示例使用 DiffControlNetLoader 节点,因为使用的控制网络是差异控制网络。差异控制网需要正确加载模型的权重。DiffControlNetLoader 节点还可用于装入常规控制网模型。加载常规 controlnet 模型时,它的行为将与 ControlNetLoader 节点相同。
![图片[17]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321155753-1024x526.webp)
您可以在 ComfyUI 中加载这些图像以获得完整的工作流程。
Pose ControlNet
这是此示例中将使用的输入图像:
![图片[18]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321155815-1024x563.webp)
这是一个示例,使用带有控制网的 AnythingV3 进行第一次通过,并使用 AOM3A3(深渊橙色混合 3)使用不带控制网的第二次通过并使用它们的 VAE。
模型合并
这些工作流背后的想法是,您可以使用多个模型合并来执行复杂的工作流,对其进行测试,然后在对结果感到满意后通过取消静音 CheckpointSave 节点来保存检查点。缺省情况下,CheckpointSave 节点将检查点保存到 output/checkpoints/ 文件夹。
您可以在以下位置找到这些节点:advanced->model_merging
第一个示例是两个不同检查点之间简单合并的基本示例。
![图片[19]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321164126-1024x567.webp)
在ComfyUI中,保存的检查点包含用于生成它们的完整工作流程,因此它们可以像图像一样加载到UI中,以获取用于创建它们的完整工作流程。
此示例是使用简单的块合并合并 3 个不同检查点的示例,其中 unet 的输入、中间和输出块可以具有不同的比率:
![图片[20]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321164150-1024x569.webp)
由于 Loras 是模型权重上的补丁,因此它们也可以合并到模型中:
![图片[21]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321164216-1024x570.webp)
您还可以减去模型权重并添加它们,如本示例所示,用于使用公式从非 inpaint 模型创建 inpaint 模型: 如果您熟悉其他 UI 中的“添加差异”选项,这就是在 ComfyUI 中执行此操作的方法。
(inpaint_model - base_model) * 1.0 + other_model![图片[22]_开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端](https://scdn.qpipi.com/2024/03/d2b5ca33bd20240321164239-1024x605.webp)
您应该注意的一件重要事情是,模型被合并并保存在用于硬件推理的精度中,因此通常它是 16 位浮点数。如果你想在 32 位浮点中进行合并,请使用以下命令启动 ComfyUI:–force-fp32
进阶手动安装 (一般用户不需要)
Git 克隆此存储库。
AMD GPU(仅限 Linux)
AMD 用户可以使用 pip 安装 rocm 和 pytorch,如果您还没有安装它,这是安装稳定版本的命令:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.7这是使用 ROCm 6.0 安装夜间的命令,可能会有一些性能改进:
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/rocm6.0Nvidia
Nvidia 用户应使用以下命令安装稳定的 pytorch:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121这是安装 pytorch 的命令,它可能会提高性能:
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu121故障 排除
如果您收到“Torch not compiled with CUDA enabled”错误,请使用以下命令卸载 torch:
pip uninstall torch然后使用上面的命令再次安装它。
依赖项
通过在 ComfyUI 文件夹中打开终端来安装依赖项,然后:
pip install -r requirements.txt在此之后,您应该已经安装了所有内容,并可以继续运行ComfyUI。
其它项
Intel Arc
Apple Mac silicon
您可以在任何最新的 macOS 版本的 Apple Mac 芯片(M1 或 M2)中安装 ComfyUI。
- 安装 pytorch。有关说明,请阅读 Mac 上的加速 PyTorch 训练 Apple 开发人员指南(确保每晚安装最新的 pytorch)。
- 按照适用于 Windows 和 Linux 的 ComfyUI 手动安装说明进行操作。
- 安装 ComfyUI 依赖项。如果您有其他 Stable Diffusion UI,则可以重用依赖项。
- 通过运行 启动 ComfyUI。请注意,–force-fp16 仅在每晚安装最新的 pytorch 时才有效。
python main.py --force-fp16
注意:记得将您的模型、VAE、LoRA 等添加到相应的 Comfy 文件夹中,如 ComfyUI 手动安装中所述。
DirectML(Windows 上的 AMD 卡)
pip install torch-directml然后,您可以使用以下命令启动ComfyUI:python main.py --directml
我已经安装了另一个用于 Stable Diffusion 的 UI,我真的必须安装所有这些依赖项吗?
你没有。如果您安装了另一个 UI 并使用它自己的 python venv,您可以使用该 venv 来运行 ComfyUI。您可以打开自己喜欢的终端并激活它:
source path_to_other_sd_gui/venv/bin/activate
或在 Windows 上:
使用 Powershell:"path_to_other_sd_gui\venv\Scripts\Activate.ps1"
使用cmd.exe:"path_to_other_sd_gui\venv\Scripts\activate.bat"
然后,您可以使用该终端运行ComfyUI,而无需安装任何依赖项。请注意,venv 文件夹可能被称为其他名称,具体取决于 SD UI。
运行
python main.py
对于 ROCm 未正式支持的 AMD 显卡
如果遇到问题,请尝试使用以下命令运行它:
对于 6700、6600 和其他 RDNA2 或更早版本:HSA_OVERRIDE_GFX_VERSION=10.3.0 python main.py
对于 AMD 7600 和其他 RDNA3 卡:HSA_OVERRIDE_GFX_VERSION=11.0.0 python main.py
希望你喜欢使用这个AI模型,就像我们创造它一样!如果您有任何问题或建议,请在评论区告诉我们。
使用Qpipi读图提示功能,获取图片TAG Prompt提示
你想要什么SD绘画模型?请在Qpipi社区或者评论留言告诉我们!
🎨享受精美的AI绘图乐趣!























- 最新
- 最热
只看作者