

国外开源网站大神cmdr2制作的Stable Diffusion一键安装包EasyDiffusion,在Github上免费开源下载。适合所有人使用,安装后可以在线升级,一直保持最新版。
在计算机上安装和使用Stable Diffusion(稳定扩散)的最简单方法。
不需要技术知识,不需要预装软件。一键安装,强大的功能,友好的社区。
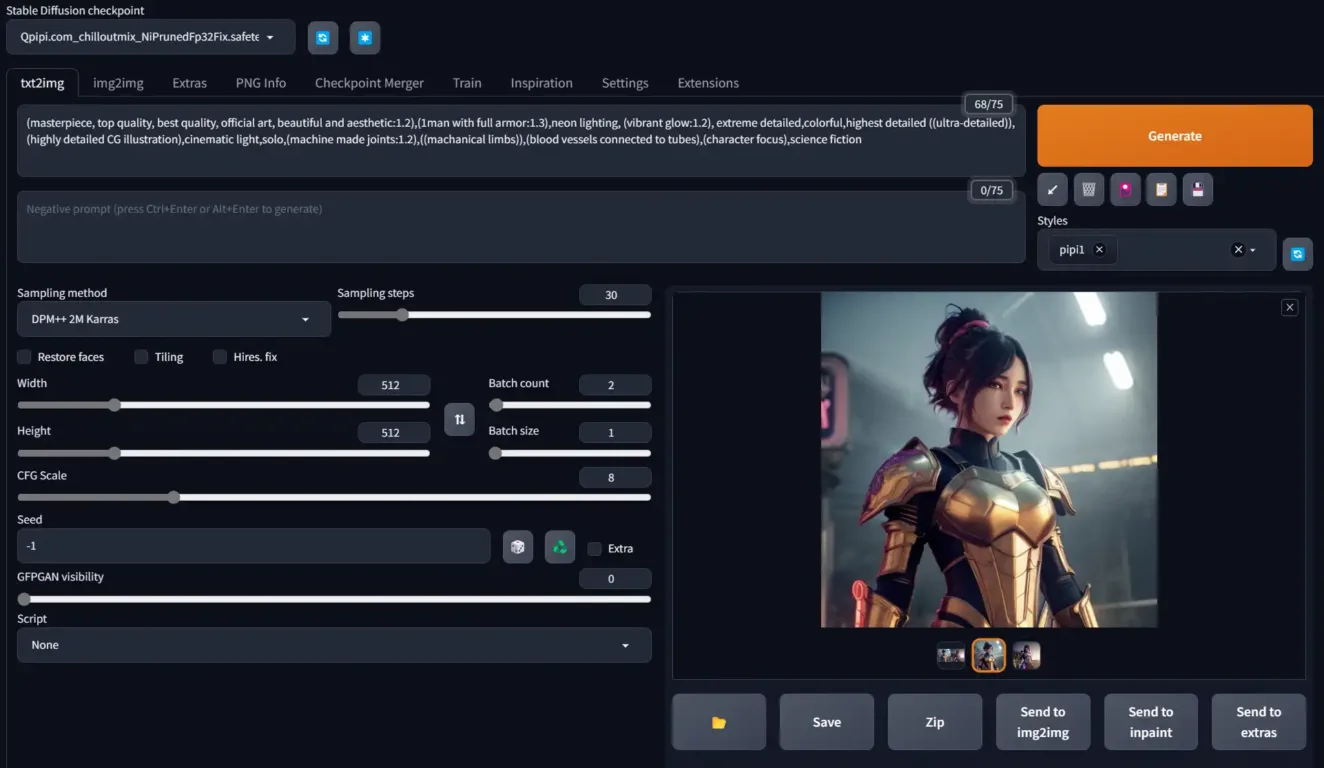
![图片[1]_Stable Diffusion一键安装懒人包新版,Easy Diffusion支持Windows、Mac绿色安装包](https://scdn.qpipi.com/2023/05/277d755772111348.webp)
开箱即用!国内首选comfyanonymous制作的 ComfyUI 现已发布:
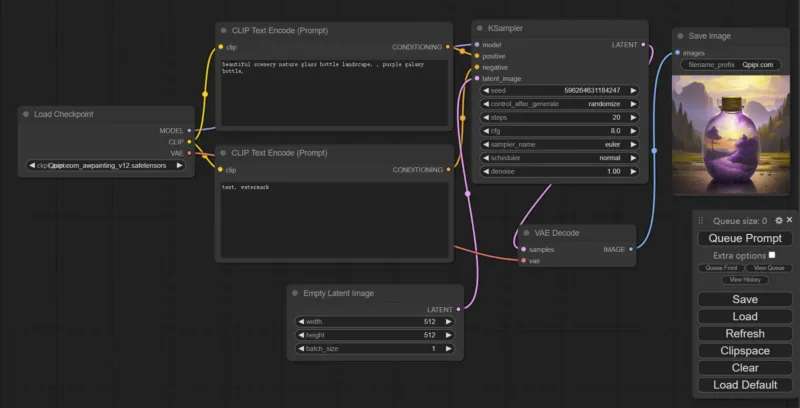
如果你有一定基础,可以手动安装Stable Diffusion,请看以下这篇:
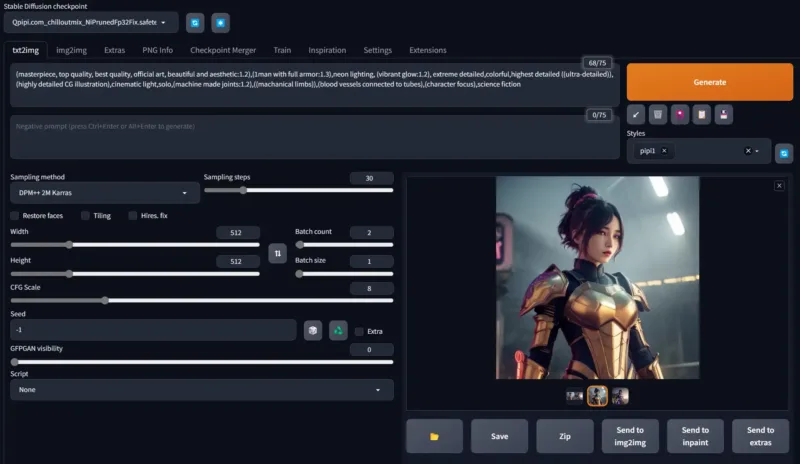
立即下载Easy Diffusion:
v3.0.2 支持SDXL、ControlNet、LoRA, Embeddings and a lot more,速度提升40%!
v3.0.2 更新内容
ControlNet - 完全支持 ControlNet,并本地集成了常见的 ControlNet 模型。只需选择一个控制图像,然后选择 ControlNet 过滤器/模型并运行。无需额外配置或下载。还支持自定义控制网络。
SDXL - 完全支持 SDXL。无需配置,只需将 SDXL 模型放在文件夹中即可。models/stable-diffusion
多个 LoRA - 使用多个 LoRA,包括 SDXL 和 SD2 兼容的 LoRA。将它们放在文件夹中。models/lora
Embeddings - 通过将文本反转嵌入放在文件夹中并在提示中使用它们的名称(或单击按钮以直观地选择嵌入),轻松使用文本反转嵌入。models/embeddings
无缝平铺 - 生成对游戏和其他美术项目有用的重复纹理。在 512x512 分辨率下效果最佳。谢谢 .
修复模型 - 完全支持修复模型,包括自定义修复模型。无需配置(或 yaml 文件)。
比 v2.5 快 - 比 Easy Difspread v2.5快近 40%,如果启用 xFormers,速度甚至更快。
VRAM使用量更少 - 在“低”显存 2GB VRAM使用(SD 1.5)下,生成512x512图像。并且可以使用 SDXL 生成大图像。
WebP 图像 - 支持以无损 webp 格式保存图像。
在 UI 中撤消 - 轻松从队列中删除任务或图像,如果意外删除了任何内容,则撤消操作。谢谢 .
三个新的采样器和潜在的升频器 - 添加了 ,并作为额外的采样器。DEIS, DDPM and DPM++ 2m SDE
图像上的“Upscale”和“Fix Faces”按钮明显更快
代码的重大重写 - 我们已改用引擎的扩散器,这使我们能够更快地发布新功能,并专注于使 UI 和安装程序更易于使用。v2.5.41 更新许多新功能:CodeFormer,AMD对Linux的支持,Latent Upscaler,在Cloudflare上共享等等!
此外,我们的新引擎可以通过启用“Beta 通道”(在“设置”选项卡中)来使用,该通道增加了对 LoRA、文本反转嵌入、平铺图像、其他采样器和改进的 VRAM 使用的实验性支持。
v2.5.41更新内容:
2.5.41 - 24 Jun 2023 - (beta-only) Fix broken inpainting in low VRAM usage mode.
2.5.41 - 24 Jun 2023 - (beta-only) Fix a recent regression where the LoRA would not get applied when changing SD models.
2.5.41 - 23 Jun 2023 - Fix a regression where latent upscaler stopped working on PCs without a graphics card.
2.5.41 - 20 Jun 2023 - Automatically fix black images if fp32 attention precision is required in diffusers.
2.5.41 - 19 Jun 2023 - Another fix for multi-gpu rendering (in all VRAM usage modes).
2.5.41 - 13 Jun 2023 - Fix multi-gpu bug with "low" VRAM usage mode while generating images.
2.5.41 - 12 Jun 2023 - Fix multi-gpu bug with CodeFormer.
2.5.41 - 6 Jun 2023 - Allow changing the strength of CodeFormer, and slightly improved styling of the CodeFormer options.
2.5.41 - 5 Jun 2023 - Allow sharing an Easy Diffusion instance via https://try.cloudflare.com/ . You can find this option at the bottom of the Settings tab. Thanks @JeLuF.
2.5.41 - 5 Jun 2023 - Show an option to download for tiled images. Shows a button on the generated image. Creates larger images by tiling them with the image generated by Easy Diffusion. Thanks @JeLuF.
2.5.41 - 5 Jun 2023 - (beta-only) Allow LoRA strengths between -2 and 2. Thanks @ogmaresca.
2.5.40 - 5 Jun 2023 - Reduce the VRAM usage of Latent Upscaling when using "balanced" VRAM usage mode.
2.5.40 - 5 Jun 2023 - Fix the "realesrgan" key error when using CodeFormer with more than 1 image in a batch.
2.5.40 - 3 Jun 2023 - Added CodeFormer as another option for fixing faces and eyes. CodeFormer tends to perform better than GFPGAN for many images. Thanks @patriceac for the implementation, and for contacting the CodeFormer team (who were supportive of it being integrated into Easy Diffusion).
2.5.39 - 25 May 2023 - (beta-only) Seamless Tiling - make seamlessly tiled images, e.g. rock and grass textures. Thanks @JeLuF.
2.5.38 - 24 May 2023 - Better reporting of errors, and show an explanation if the user cannot disable the "Use CPU" setting.
2.5.38 - 23 May 2023 - Add Latent Upscaler as another option for upscaling images. Thanks @JeLuF for the implementation of the Latent Upscaler model.
2.5.37 - 19 May 2023 - (beta-only) Two more samplers: DDPM and DEIS. Also disables the samplers that aren't working yet in the Diffusers version. Thanks @ogmaresca.
2.5.37 - 19 May 2023 - (beta-only) Support CLIP-Skip. You can set this option under the models dropdown. Thanks @JeLuF.
2.5.37 - 19 May 2023 - (beta-only) More VRAM optimizations for all modes in diffusers. The VRAM usage for diffusers in "low" and "balanced" should now be equal or less than the non-diffusers version. Performs softmax in half precision, like sdkit does.
2.5.36 - 16 May 2023 - (beta-only) More VRAM optimizations for "balanced" VRAM usage mode.
2.5.36 - 11 May 2023 - (beta-only) More VRAM optimizations for "low" VRAM usage mode.
2.5.36 - 10 May 2023 - (beta-only) Bug fix for "meta" error when using a LoRA in 'low' VRAM usage mode.
2.5.35 - 8 May 2023 - Allow dragging a zoomed-in image (after opening an image with the "expand" button). Thanks @ogmaresca.
2.5.35 - 3 May 2023 - (beta-only) First round of VRAM Optimizations for the "Test Diffusers" version. This change significantly reduces the amount of VRAM used by the diffusers version during image generation. The VRAM usage is still not equal to the "non-diffusers" version, but more optimizations are coming soon.
2.5.34 - 22 Apr 2023 - Don't start the browser in an incognito new profile (on Windows). Thanks @JeLuF.
2.5.33 - 21 Apr 2023 - Install PyTorch 2.0 on new installations (on Windows and Linux).
2.5.32 - 19 Apr 2023 - Automatically check for black images, and set full-precision if necessary (for attn). This means custom models based on Stable Diffusion v2.1 will just work, without needing special command-line arguments or editing of yaml config files.
2.5.32 - 18 Apr 2023 - Automatic support for AMD graphics cards on Linux. Thanks @DianaNites and @JeLuF.
2.5.31 - 10 Apr 2023 - Reduce VRAM usage while upscaling.
2.5.31 - 6 Apr 2023 - Allow seeds upto . Thanks @ogmaresca.4,294,967,295
2.5.31 - 6 Apr 2023 - Buttons to show the previous/next image in the image popup. Thanks @ogmaresca.
2.5.30 - 5 Apr 2023 - Fix a bug where the JPEG image quality wasn't being respected when embedding the metadata into it. Thanks @JeLuF.
2.5.30 - 1 Apr 2023 - (beta-only) Slider to control the strength of the LoRA model.
2.5.30 - 28 Mar 2023 - Refactor task entry config to use a generating method. Added ability for plugins to easily add to this. Removed confusing sentence from contributing.md
2.5.30 - 28 Mar 2023 - Allow the user to undo the deletion of tasks or images, instead of showing a pop-up each time. The new button will be present at the top of the UI. Thanks @JeLuF.Undo
2.5.30 - 28 Mar 2023 - Support saving lossless WEBP images. Thanks @ogmaresca.
2.5.30 - 28 Mar 2023 - Lots of bug fixes for the UI (Read LoRA flag in metadata files, new prompt weight format with scrollwheel, fix overflow with lots of tabs, clear button in image editor, shorter filenames in download). Thanks @patriceac, @JeLuF and @ogmaresca.
2.5.29 - 27 Mar 2023 - (beta-only) Fix a bug where some non-square images would fail while inpainting with a error.The size of tensor a must match size of tensor b
2.5.29 - 27 Mar 2023 - (beta-only) Fix the error, when given a PNG image with an alpha channel in .incorrect number of channelsTest Diffusers
2.5.29 - 27 Mar 2023 - (beta-only) Fix broken inpainting in .Test Diffusers
2.5.28 - 24 Mar 2023 - (beta-only) Support for weighted prompts and long prompt lengths (not limited to 77 tokens). This change requires enabling the setting in beta (in the Settings tab), and restarting the program.Test Diffusers
2.5.27 - 21 Mar 2023 - (beta-only) LoRA support, accessible by enabling the setting (in the Settings tab in the UI). This change switches the internal engine to diffusers (if the setting is enabled). If the flag is disabled, it'll have no impact for the user.Test DiffusersTest DiffusersTest Diffusers
2.5.26 - 15 Mar 2023 - Allow styling the buttons displayed on an image. Update the API to allow multiple buttons and text labels in a single row. Thanks @ogmaresca.
2.5.26 - 15 Mar 2023 - View images in full-screen, by either clicking on the image, or clicking the "Full screen" icon next to the Seed number on the image. Thanks @ogmaresca for the internal API.
2.5.25 - 14 Mar 2023 - Button to download all the images, and all the metadata as a zip file. This is available at the top of the UI, as well as on each image. Thanks @JeLuF.
2.5.25 - 14 Mar 2023 - Lots of UI tweaks and bug fixes. Thanks @patriceac and @JeLuF.提示:安装后可以在线升级至最新版(SD、ESD核心、模块、测试版等在线更新),这里提供得到的稳定版旧版,启动时会在线升级至最新版,无需重新安装。
国外下载:
https://github.com/cmdr2/stable-diffusion-ui/releases
国内Qpipi.com下载:
Easy Windows installer包含了Stable Diffusion本体和代码库,第一次运行时需要下载一些模组
Easy Diffusion安装:
在计算机上安装和使用Stable Diffusion(稳定扩散)的最简单方法。
不需要技术知识,不需要预装软件。一键安装,强大的功能,友好的社区。
国内用户必看:需修改HOSTS文件,解决Git无法下载和下载缓慢问题!
首先编辑你的hosts文件,文件路径默认在 C:/WINDOWS/system32/drivers/etc/(视乎你的Windows安装路径,windows安装安在什么盘就去什么盘里找)
右键hosts文件,选择打开方式,可以用记事本编辑
在文件最后增加两行,对应IPv4/IPv6访问:
新增:国内经常下载失败导致无法画图的 pytorch_model.bin 文件
ESD默认模型:v1-5-pruned-emaonly
SDW默认模型:sd-v1-4
GFPGANv1.4下载
其它一些常见问题解答

硬件要求:
- Windows: NVIDIA graphics card, or run on your CPU.
- Linux: NVIDIA or AMD graphics card, or run on your CPU.
- Mac: M1 or M2, or run on your CPU.
- Minimum 8 GB of system RAM.
- Atleast 25 GB of space on the hard disk.
在Windows上:
- 运行下载的文件。
Easy-Diffusion-Windows.exe - 安装完成后运行。您也可以从“开始”菜单或桌面(如果您创建了快捷方式)开始。
Easy Diffusion
如果 Windows 智能屏幕阻止您运行该程序,请单击允许 。More info / Run anyway
提示:在 Windows 10 上,请安装在驱动器的顶层,例如 或。这将避免 Windows 10 的常见问题(文件路径长度限制)。C:\EasyDiffusion D:\EasyDiffusion
在 Linux/Mac 上:
- 解压缩/解压缩应位于下载文件夹中的文件夹,除非您更改了默认下载目的地。
easy-diffusion - 打开终端窗口,然后导航到该目录。
easy-diffusion - 在终端中运行(或)。
./start.shbash start.sh
删除/卸载:
只需删除该文件夹即可卸载所有下载的软件包。EasyDiffusion
模型下载
目前国内可以在SD绘图模型主体-Qpipi.com下载SD模型主体和插件
SD提示指令
如果想有一个好作品离不开好的提示,你可以在SD绘图作品展示-Qpipi.com查看作品并复制提示。
绘图作品发布
SD绘制的作品可以在Stable Diffusion作品展示社区发布。
Easy Diffusion的特征:
对新用户来说很容易,对高级用户来说功能强大
用户体验
- 轻松安装:不需要技术知识,不需要预装软件。只需下载并运行!
- 整洁的UI:友好而简单的UI,同时提供了许多强大的功能。
- 任务队列:将所有想法排队,而无需等待当前任务完成。
- 智能模型检测:自动找出用于所选模型的 YAML 配置文件(通过模型数据库)。
- 实时预览:在 AI 绘制图像时查看图像。
- 图像修改器:一个修改器标签库,如“逼真”,“铅笔素描”,“ArtStation”等。快速尝试各种样式。
- 多个提示文件:通过每行输入一个提示或运行文本文件来对多个提示进行排队。
- 将生成的图像保存到磁盘:将图像保存到PC!
- UI主题:根据自己的喜好自定义程序。
- 可搜索模型下拉列表:将模型组织到子文件夹中,并在 UI 中搜索它们。
图像生成
- 支持:“文本到图像”和“图像到图像”。
- 19 种采样器:
ddim,plms,heun,euler,euler_a,dpm2,dpm2_a,lms,dpm_solver_stability,dpmpp_2s_a,dpmpp_2m,dpmpp_sde,dpm_fast,dpm_adaptive,unipc_snr,unipc_tu,unipc_tq, unipc_snr_2,unipc_tu_2 - 画中:指定要绘制到的图像区域。
- 简单的绘图工具:绘制基本图像以指导AI,而无需外部绘图程序。
- 面部矫正
- 升级(RealESRGAN)
- 环回:使用输出图像作为下一个 img2img 任务的输入图像。
- 负面提示:指定要删除的图像的各个方面。
- 注意/强调:提示中的 () 增加了模型对封闭单词的注意,而 [] 减少了它。
- 加权提示:在提示中使用特定单词的权重来更改其重要性,例如:
red:2.4 dragon:1.2 - 提示矩阵:快速创建提示的多个变体,例如:a photograph of an astronaut riding a horse | illustration | cinematic lighting
- 一键放大/面部校正:在生成图像后放大或校正图像。
- 制作相似图像:单击以生成生成的图像的多个变体。
- NSFW 设置:UI 中用于控制 NSFW 内容的设置。
- JPEG/PNG/WEBP 输出:多种文件格式。
高级功能
- 自定义模型:使用您自己的或文件.ckpt / .safetensors,将其放在你的安装目录/models/stable-diffusion文件夹!
- Stable Diffusion 2.1 支持
- 合并模型
- 使用定制VAE型号
- 使用预先训练的超网络
- 使用自定义 GFPGAN 模型
- UI 插件:从不断增长的社区生成的 UI 插件列表中选择,或编写自己的插件为项目添加功能!
性能和安全性
- 快速:Creates a 512×512 image with euler_a in 5 seconds, on an NVIDIA 3060 12GB.
- 低内存使用量:Create 512×512 images with less than 3 GB of GPU RAM, and 768×768 images with less than 4 GB of GPU RAM!
- 使用 CPU 设置:如果您没有兼容的显卡,但仍想在 CPU 上运行它。
- 多 GPU 支持:自动将您的任务分散到多个 GPU(如果可用),以获得更快的性能!
- 自动扫描恶意模型:使用 picklescan 阻止恶意模型。
- 安全张量支持:支持以安全张量格式加载模型,以提高安全性。
- 自动更新程序:为您提供快速发展的项目的最新改进和错误修复。
- 开发人员控制台:一种开发人员模式,适用于想要修改其稳定扩散代码和编辑 conda 环境的用户。
(以及更多)
SD绘图作品专区和绘图提示指令:SD绘图作品展示-Qpipi




查看更多:SD绘图作品展示-Qpipi
SD模型下载:
中国用户可以在Qpipi.com获取最新绘图模型主体和插件!包括SD绘图模型主体-Qpipi、SD绘图美化优化-Qpipi、SD绘图插件-Qpipi等。
SD提示指令:
中国用户在SD绘图作品展示-Qpipi获得完整的SD绘图提示,包括一个SD社区首页
绘图作品发布:
当你通过SD完成了一件绘图作品,可以到Stable Diffusion作品展示版块发布你的作品。
欢迎错误报告和代码贡献
如果有任何问题或建议,请随时询问或提出问题。
如果您有任何代码贡献,请随时向我们打招呼。
相关来源:
SD相关的下载 Stable Diffusion-Qpipi
SD绘图作品展示 SD绘图作品展示-Qpipi
SD精选模型下载SD绘图模型主体-Qpipi
SD优化/美化模型下载SD绘图美化优化-Qpipi
SD插件下载SD绘图插件-Qpipi
Qpipi.com
希望你喜欢使用这个AI模型,就像我们创造它一样!如果您有任何问题或建议,请在评论区告诉我们。
使用Qpipi读图提示功能,获取图片TAG Prompt提示
你想要什么SD绘画模型?请在Qpipi社区或者评论留言告诉我们!
🎨享受精美的AI绘图乐趣!























- 最新
- 最热
只看作者