

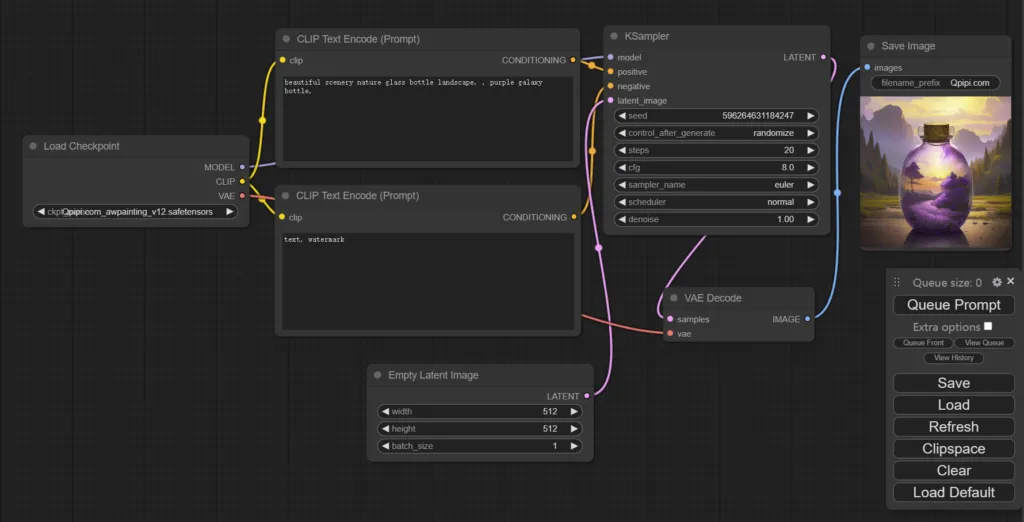
SDXL 由用于潜在扩散的两步流水线组成:首先,我们使用基本模型生成所需输出大小的潜在流水线。在第二步中,我们使用专门的高分辨率模型,并使用相同的提示将称为SDEdit(https://arxiv.org/abs/2108.01073,也称为“img2img”)的技术应用于第一步中生成的潜在。
![图片[1]_SDXL 基础训练大模型全系列](https://scdn.qpipi.com/2023/07/6b7a935b07170516.webp)
型号说明
- 开发方:稳定性人工智能
- 型号类型:基于扩散的文本到图像生成模型
- 许可证:SDXL 0.9 研究许可证
- 型号说明:这是一个模型,可用于根据文本提示生成和修改图像。它是一个潜在扩散模型,使用两个固定的、预训练的文本编码器(OpenCLIP-ViT/G 和 CLIP-ViT/L)。
- 更多信息的资源:GitHub 存储库。
模型源
- SDXL-base-1.0: An improved version over
SDXL-base-1.0. - SDXL-refiner-1.0: An improved version over
SDXL-refiner-1.0. - SDXL-Lightning
- 存储库:https://github.com/Stability-AI/generative-models
- 演示 [可选]: https://clipdrop.co/stable-diffusion
更新国内下载:sd_xl_base_1.0_0.9vae.safetensors 、 sd_xl_refiner_1.0_0.9vae.safetensors
使用
直接使用
该模型仅用于研究目的。可能的研究领域和任务包括
- 艺术品的生成和用于设计和其他艺术过程。
- 在教育或创意工具中的应用。
- 生成模型研究。
- 安全部署可能生成有害内容的模型。
- 探索和理解生成模型的局限性和偏差。
排除的用途如下所述。
超出范围使用
该模型未经过训练,无法真实地表示人或事件,因此使用该模型生成此类内容超出了该模型的功能范围。
限制和偏见
局限性
- 该模型没有达到完美的照片级真实感
- 模型无法呈现清晰的文本
- 该模型努力处理涉及构图的更困难的任务,例如渲染对应于“蓝色球体顶部的红色立方体”的图像
- 一般情况下,人脸和人物可能无法正确生成。
- 模型的自动编码部分是有损的。
偏见
虽然图像生成模型的功能令人印象深刻,但它们也会加强或加剧社会偏见。
![图片[2]_SDXL 基础训练大模型全系列](https://scdn.qpipi.com/2023/07/5e4183211c170540.webp)
上图评估了用户对 SDXL(有和没有优化)相对于稳定扩散 1.5 和 2.1 的偏好。SDXL 基本模型的性能明显优于以前的变体,并且模型与细化模块相结合可实现最佳的整体性能。
希望你喜欢使用这个AI模型,就像我们创造它一样!如果您有任何问题或建议,请在评论区告诉我们。
使用Qpipi读图提示功能,获取图片TAG Prompt提示
你想要什么SD绘画模型?请在Qpipi社区或者评论留言告诉我们!
🎨享受精美的AI绘图乐趣!
© 版权声明
分享是一种美德,转载本站图文等内容,请保留 Qpipi.com 原文链接,谢谢你的支持!
THE END


























- 最新
- 最热
只看作者