


我厌倦了传统 AI 绘画一成不变的脸、姿势、风格,所以想要脱离混合模型。最初,我使用提示词,可始终无法达成某种微妙的线条、色彩、光影、质感、构图或故事性,甚至无法复刻模型偶然产生的惊艳风格。
![图片[1]_Anime Illust Diffusion AI绘图模型,动漫插画扩散](https://scdn.qpipi.com/2023/07/6af2035bd8213911-1365x768.webp)
![图片[2]_Anime Illust Diffusion AI绘图模型,动漫插画扩散](https://scdn.qpipi.com/2023/07/1861aa0827213903-1280x768.webp)
![图片[3]_Anime Illust Diffusion AI绘图模型,动漫插画扩散](https://scdn.qpipi.com/2023/07/26333f7621213900-1152x768.webp)
这种昙花一现仅与一般风格有细微差别,却从美学上引人入胜。因此,我想制作一种能完美学习艺术风格并稳定输出的模型。我从 2022 年 11 月开始收集素材训练风格化模型,特殊打标以区分那些仅有细微差异的素材,终于于 2023 年年初在模型风格上自成一派,即 AIDv1.0 模型。
为什么不练 Lora 而要微调?我始终认为微调的效果要优于 Lora。它不依赖于底模,所有的训练图像在训练中共同向着误差最低点前进,而不仅是最优化一块附加权重。但我也在探寻能够将特定风格完美融入大模型的方法,以减轻训练负担。
此后半年里,我自费两万多元,亲自裁图、打标、魔改脚本。训练步数从几千,几万再到几百万,训练设备从 RTX3060,RTX3090 再到 A100。从制作素材再到训练,AID 也逐渐成为了架构完整的工程项目。
在这之中,我发现只有当模型轻微“过拟合”到原图像的噪点时,才能对风格有最佳的学习。我尝试过拟合所有风格,并使用负面 emb 学习过拟合噪点以平衡不同风格间的学习进度,由此制作了 bad, badhand 和 aid 系列。这种正则化方法为我带来了很好的结果。一个训练恰到好处的负面 emb 不仅不会破坏底模的风格,还能助长风格的特征。
随着模型迭代,我认为我逐渐达到了 SD1.5 的上限。即便是微调,那些精美插画风格独特的线条、色彩、光影、构图、故事性各具特色而难以简单的 SD1.5 模型很好地学习模仿。从欠拟合到过拟合,我始终无法得到完美的风格化特征,更何况模型同时需要最优化百种以上的艺术风格。
为此,我非常期待更加复杂的 SDXL 模型能为我带来新的突破口。
模型训练期间,我并没有将精力耗费在撰写大量提示词和混合不同风格上。有人搭配一些 Lora 和非常复杂的提示词得到了相当惊艳的结果,我非常感谢他们的创新和喜爱。
最后,感谢 @BananaCat 对本文的汉化,我很乐意与全世界的 SD 爱好者分享和交流成果。AID 模型均出于专业兴趣。如果您对更多素材处理和模型训练的工程细节感兴趣,或愿意与我分享您的训练方案,欢迎在评论区留言,我会第一时间回复。
![图片[4]_Anime Illust Diffusion AI绘图模型,动漫插画扩散](https://scdn.qpipi.com/2023/07/70e5aa75e0213855-432x768.webp)
![图片[5]_Anime Illust Diffusion AI绘图模型,动漫插画扩散](https://scdn.qpipi.com/2023/07/2d2446281e213921-528x768.webp)
![图片[6]_Anime Illust Diffusion AI绘图模型,动漫插画扩散](https://scdn.qpipi.com/2023/07/a7aca56203213843-432x768.webp)
I 介绍
AnimeIllustDiffusion (AID) 是一款预训练、非商用且多风格的动漫插画模型。它 不会生成“AI脸”。它内置大量风格,您能够使用一些 特殊的触发词(见 附录 A)来生成特定风格的图像。由于内置大量内容,AID 需要强烈的负面提示才能正常工作。一般的负面提示词(例如 low quality, bad anatomy 等)效果有限,因此,若您生成的图像中出现噪点,请搭配我提供的负面文本嵌入 [1] 使用,以消除噪声。对于版本特制负面文半嵌入,请 参阅版本信息。另外,我推荐 sd-vae-ft-mse-original [5] 这款 vae,它色彩明亮,非常适合插画风格。第 II 部分将简单地介绍 AnimeIllustDiffusionV1.0 的制作过程;第 III 部分将介绍负面文本嵌入;附录 A 部分将提供完整的关键词列表。
请在下载前仔细浏览所下载版本的版本信息!!!
AID 模型拥有 超过 200 种 稳定的 动漫插画风格 和 100 名动漫角色。生成风格需要的特殊提示词见附录 A。生成角色则直接使用角色名即可。AID 模型像一个调色板,您可以通过任意组合提示词创造出新的风格。
1 推荐参数
采样器:Euler a
采样步数:40
分辨率:512×768, 640×960, 768×1152 等
CLIP 层跳过:1
提示词格式: best quality, masterpiece, highres, by {xxx}, best lighting and shadow, stunning color, radiant tones, ultra-detailed, amazing illustration, an extremely delicate and beautiful, {其他提示词}
负面提示词格式:aid210, {其他负面提示词}
ps: 其中,`{xxx}` 为风格名称。`aid210` 为模型特制负面文本嵌入。您可以从 [1] 的链接处下载并学习如何使用它。
2 版本比较
每个版本的 AID 各有所长,并非越新的版本越好。
- 适合第一次使用:v2.8, v2.91 – Weak, v2.10beta1
- 有极佳创造力:v2.6, v2.7, v2.91 – Weak, v2.91 – Strong
- 较为稳定:v2.5, v2.6, v2.8, v2.91 – Weak
- 风格多样:v2.91 – Weak, v2.91 – Strong, v2.10beta1
II 模型
这款模型由三个不同的模型融合而来,其中两个由我训练,另一个为 GoldSun 融合的 Pretty 2.5D 模型 [2]。
1 模型训练
我使用 4300+ 张经过人工裁剪、打标、512×512尺寸的二次元插画图像作为训练集,使用 dreambooth 微调 Naifu 7G 大模型训练风格。我以较高的学习率为每张训练集图像训练了100期。我没有使用正则化图像。我训练了文本编码器。如果有兴趣,您可以在 [3] 处找到详细参数信息。
2 模型融合
我使用 Merge Block Weighted 扩展融合模型。在三个模型中,一个模型被用于提供风格和文本编码器(base alpha 和全部 OUT 层),一个模型被用于优化手部细节(IN 层 00 – 05),另一个模型(Pretty 2.5D)被用于提供构图(IN 层 06 – 11 和 M 层)。
III 负面文本嵌入
该模型推荐使用 badv3 —— 一个负面提示词的文本嵌入文件。它不仅能简化提示词的书写,还能激发模型潜力,提高生成图片的质量。通常,badv3 的效果已经足够,您无需再额外填写质量提示词。但它并不能解决 100% 的画面问题。
1 使用方法
您应该将下载得到的负面文本嵌入文件,即 badv3.pt 文件放置在您 stable diffusion 目录下的 embeddings 文件夹内。之后,您只需要在填写负面提示词处输入 badv3 即可。
2 制作思路
我的想法是训练了一个糟糕图像的概念,并把它放入负面提示词中以避免生成这类不好的图像。
我使用了几百张由模型生成的糟糕图像训练负面文本嵌入,即 badv3,其原理与 EasyNegative [4] 相似。我尝试把它训练到过拟合以缓解传统负面文本嵌入对模型画风的影响,这似乎很有效。
与 EasyNegative 相比,badv3 对本模型的效果要更好。我暂未对比其他负面文本嵌入。
badv3 是我继 deformityv6 后训练的第 n 个负面文本嵌入。其制作非常容易,但结果也相当随机。我曾尝试通过添加差分来从模型中移除另一个用糟糕图像训练的模型的权重,但目前并没有乐观的结果。我接下来打算训练负面 Lora 来代替负面文本嵌入以直接从模型中“移除”一部分权重而非“避免”它们。
🎨希望你喜欢使用它,就像我喜欢创造它一样!如果您有任何问题或建议,请随时分享。享受创造惊人图像的乐趣!
作品展示和提示

安装说明

下载SD绘图工具
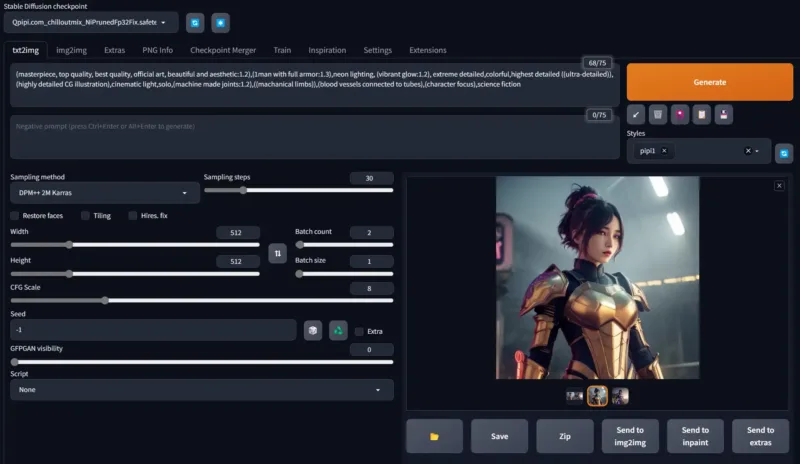
希望你喜欢使用这个AI模型,就像我们创造它一样!如果您有任何问题或建议,请在评论区告诉我们。
使用Qpipi读图提示功能,获取图片TAG Prompt提示
你想要什么SD绘画模型?请在Qpipi社区或者评论留言告诉我们!
🎨享受精美的AI绘图乐趣!











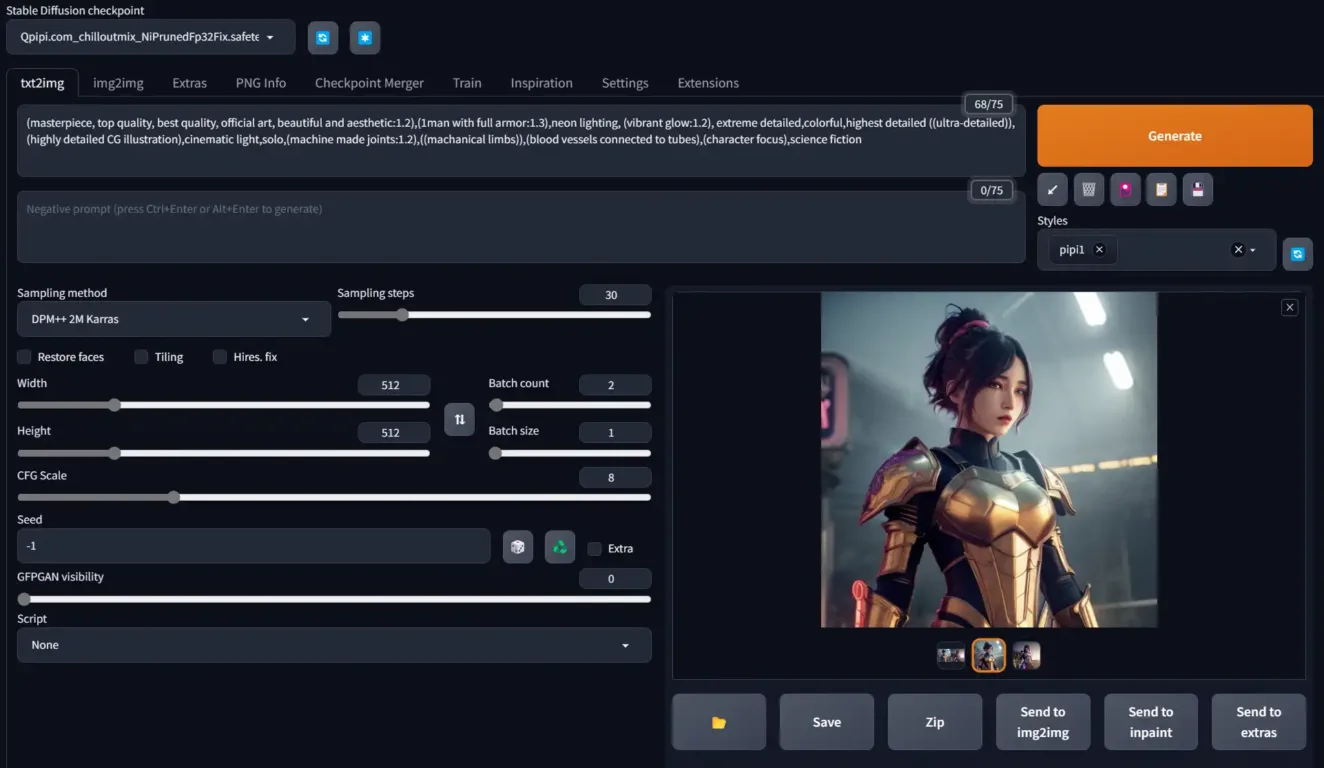

















- 最新
- 最热
只看作者