



与SD1.5基本模型“MoonFilm”不同,“HelloWorld”是一个全新的逼真的SDXL基本模型系列。为了让更多的用户发现HelloWorld,我保留了原有的Moonfilm的模型链接。
它可以被看作是 Moonfilm 在 SDXL 新平台上的精神延续,但 HelloWorld 的目标不仅仅是追求人像的真实感和电影般的品质。与SD1.5相比,SDXL的信息量和文本理解能力要强得多,HelloWorld是一个基本模型,旨在逼真地描绘所有事物,或者换句话说,我希望使用HelloWorld逐步构建一个虚拟摄影世界。
![图片[1]_HelloWorld XL AI绘图模型,更好的文本理解和电影般品质](https://scdn.qpipi.com/2024/04/7bf0ff8c0920240421092147-677x1024.webp)
![图片[2]_HelloWorld XL AI绘图模型,更好的文本理解和电影般品质](https://scdn.qpipi.com/2024/04/64064f210020240421092148-677x1024.webp)
![图片[3]_HelloWorld XL AI绘图模型,更好的文本理解和电影般品质](https://scdn.qpipi.com/2024/04/3851152d8320240421092150-677x1024.webp)
![图片[4]_HelloWorld XL AI绘图模型,更好的文本理解和电影般品质](https://scdn.qpipi.com/2024/04/047ff8699f20240421092122-634x1024.webp)
![图片[5]_HelloWorld XL AI绘图模型,更好的文本理解和电影般品质](https://scdn.qpipi.com/2024/04/966c18160320240421092125-677x1024.webp)
![图片[6]_HelloWorld XL AI绘图模型,更好的文本理解和电影般品质](https://scdn.qpipi.com/2024/04/96ae2b96c620240421092142-677x1024.webp)
以下是 6.0 版中的主要更新:
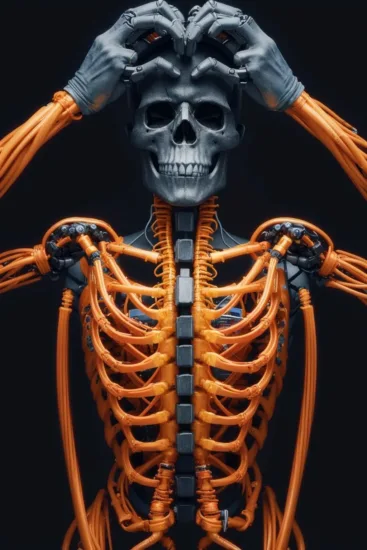
- HelloWorld 6.0 是基于版本 5.0 的迭代改进。根据我自己的测试,真实感效果与 5.0 版本没有显着差异。6.0 版的主要优点在于它更广泛地覆盖了训练集中的概念。根据反馈,各种主题都得到了增强,包括超现实主义、闺房、合影、面具、折纸、3D 渲染、汽车、龙和孕妇摄影。图中提供了一些示例。
- HelloWorld 6.0 有意在训练中包含一些低质量的图像,以增强模型对负面提示的响应。建议在否定提示中使用以下术语:“低质量、jpeg 伪影、模糊、绘制不佳、丑陋、质量最差”。
- HelloWorld 6.0 训练集的主体采用 GPT4v 标记。对于 GPT4v 无法标记的图像,使用 blip2-opt-6.7b 引导的 cogVQA 进行标记。这些多模态模型的标记语言风格与传统的 WD1.4 标记器有很大不同。为了方便更准确地触发训练集中的不同概念,我整理了 HelloWorld 6.0 训练集中排名前 250 位的高频标记词。
最后,虽然SD3即将发布,但我还是会更新到HelloWorld XL 7.0,希望在7.0版本中实现更大的增强!
![图片[7]_HelloWorld XL AI绘图模型,更好的文本理解和电影般品质](https://scdn.qpipi.com/2024/03/51872ce66b20240331102020-677x1024.webp)
![图片[8]_HelloWorld XL AI绘图模型,更好的文本理解和电影般品质](https://scdn.qpipi.com/2024/03/8d56ee7fde20240331102023-677x1024.webp)
![图片[9]_HelloWorld XL AI绘图模型,更好的文本理解和电影般品质](https://scdn.qpipi.com/2024/03/00f5b5886020240331102020-677x1024.webp)
SD1.5 的现实基础模型已经发展到相当成熟的阶段,不太可能有明显的性能提升。除非SD1.5平台有突破性技术,否则Moonfilm & MoonMix系列基本上会停止更新。我将把主要精力投入到HelloWorld SDXL大型模型的开发中。
v5Lightning 此模型是 HelloWorld SDXL 基本模型的运行加速版本,融合了 SDXL-Lightning 技术。配备 Eular a 采样器和 CFG 1,它能够以 6-8 个步骤生成图像,比原始 SDXL 版本快三倍。此外,经过比较,其成像效果优于 LCM 或 Turbo 版本。
使用此模型生成图像的推荐参数为:
采样器:Eular a(重要!该模型专门适用于 Eular a,其他采样器可能不会产生良好的结果)
CFG scale: 1
Sampling steps: 8 steps (6~8 steps are acceptable)
Hires algorithm: ESRGAN 4x / 8x_NMKD-Faces_160000_G
Hires Upscale factor: 1.5x
Hires steps: 8 steps
Hires Denoising strength: 0.3
经过多轮测试,建议的绘图参数设置为:
- 步骤 ≥ 25
- 采样器:DPM++ 2M Karras
- CFG 量表:10
- 尺寸 ≥ 1024×1024
- ADetailer:开放
![图片[10]_HelloWorld XL AI绘图模型,更好的文本理解和电影般品质](https://scdn.qpipi.com/2024/03/f147f6a2c920240331102018-677x1024.webp)
![图片[11]_HelloWorld XL AI绘图模型,更好的文本理解和电影般品质](https://scdn.qpipi.com/2024/03/f874bda1c220240331102025.webp)
![图片[12]_HelloWorld XL AI绘图模型,更好的文本理解和电影般品质](https://scdn.qpipi.com/2024/03/af7a4b8a2520240331102014-677x1024.webp)
HelloWorld 5.0GPT4v 是 HelloWorld 系列历史上最重大的更新,标记为 GPT-4v,并在科幻、动物、建筑和插图等领域进行了重大微调。
对比测试表明,此版本的改进包括:
1.更多样化和动态的人物姿势和图像构图,创造出视觉上引人入胜的画面;
2. 胶片数据集经过广泛训练。虽然从 2.0 版到 4.0 版的电影质感很弱,但很多粉丝怀念 1.0 版的 leogirl 风格。因此,此更新特别增强了胶片纹理,同时不影响其他摄影质量。胶片纹理可以通过胶片颗粒纹理和模拟摄影美学等短语触发;
3. 增强了科幻、惊悚和动物等主题的表现力,机甲和其他主题更具设计感。雪豹、小熊猫、大熊猫、老虎、帕拉斯猫、家猫狗等动物更加逼真;
4. 得益于 GPT 标记,及时遵守和概念准确性得到进一步提高。
但是,此版本的缺点包括:
1. 由于这是一次实质性的微调更新,因此肢体等的错误率可能会略有增加,这是走出舒适区进入相对优化的新领域时的正常现象。以前的版本经过了广泛的肢体测试以进行改进,而新版本进行此类改进的时间有限。尽管如此,此版本中肢体的准确性至少高于 1.0 版本,我将在未来的更新中继续进行改进。
2. 由于强化的胶片纹理,即使 GPT 标记尽可能准确,图像中也可能不可避免地存在默认暖色调。但是,您可以使用工作室灯光或锐利对焦等提示来生成高清工作室质量的图像,并且通过正确使用提示,输出可以比以前的版本具有更好的肤色和视觉吸引力。
3.此版本包含更多的全身角色图像以增强全身效果,因此如果没有特定的角色构图,模型可能会产生比以前更宽的场景。目前,与半身或特写镜头相比,1024分辨率全身照片中的面部细节可能不那么清晰。但是,这可以通过 adetailer 和 1.5x Hire 来改善。固定在 0.3 强度,或使用指定构图等提示来避免生成全身图像。
4. 由于添加了少量高质量的插图数据集,因此与动画样式相关的提示可能会产生动画图像。如果您对此感到担忧,请相应地调整您的提示。
这些是此版本的主要更新。训练 SDXL 基础模型具有挑战性,当训练集接近一万张图像时,每个模型的标记和训练成本超过 300 美元。我欢迎大家使用该模型,并感谢您提供的任何反馈!如果您觉得这个模型令人满意,如果您能帮助传播它,我将不胜感激。
![图片[13]_HelloWorld XL AI绘图模型,更好的文本理解和电影般品质](https://scdn.qpipi.com/2024/03/64a235b94120240331102012-677x1024.webp)
![图片[14]_HelloWorld XL AI绘图模型,更好的文本理解和电影般品质](https://scdn.qpipi.com/2024/03/b48e34672920240331102014-677x1024.webp)
![图片[15]_HelloWorld XL AI绘图模型,更好的文本理解和电影般品质](https://scdn.qpipi.com/2024/03/9e150d536320240331102007-677x1024.webp)
HelloWorld4.0 是一个渐进式过渡版本,从使用 blip+clip 标记到使用 GPT4V 标记。我最初训练了一个纯 GPT4V 标签模型,然后将其与大部分 HelloWorld3.2 版本和 0.05 比例的 Juggernaut XL 合并(以调整肤色)。与 3.2 版本相比,新版本在及时合规性和概念覆盖率方面有所改进。
新的 GPT4V 标记训练集从 helloworld3 系列的 4000 张图像增加到 8000 张图像,不仅涵盖了肖像,还涵盖了动物、建筑、自然、食物、插图等。然而,纯GPT4V版本遇到了过拟合问题,初步归因于训练图像数量翻倍。迭代优化的下一步是找出如何包含尽可能多的非人像概念,同时确保对人像进行充分的训练。现阶段,已经使用了新旧版本的融合进行微调,以确保版本之间的平滑过渡,因此扩展的概念集和 GPT4V 标签带来的优势目前还不是很明显。这些优势将在该模型的后续第 5 代和第 6 代中变得越来越明显。
AI绘画作品展示


AI绘图常用工具
希望你喜欢使用这个AI模型,就像我们创造它一样!如果您有任何问题或建议,请在评论区告诉我们。
使用Qpipi读图提示功能,获取图片TAG Prompt提示
你想要什么SD绘画模型?请在Qpipi社区或者评论留言告诉我们!
🎨享受精美的AI绘图乐趣!


























暂无评论内容