



AnyLoRA Anime Mix (AAM) Anime Screencap Style Model 动漫屏幕截图风格模型
LCM 版本。使用 5-15 步,~2 cfg。它仅适用于 LCM 采样器(要在 Auto1111 上获取它,您目前需要一个插件)。
![图片[1]_AAM AnyLoRA Anime Mix AI绘图模型,动漫屏幕截图风格模型](https://scdn.qpipi.com/2023/06/6811158a2620240403233406-684x1024.webp)
![图片[2]_AAM AnyLoRA Anime Mix AI绘图模型,动漫屏幕截图风格模型](https://scdn.qpipi.com/2023/06/002270c65f20240403233409.webp)
![图片[3]_AAM AnyLoRA Anime Mix AI绘图模型,动漫屏幕截图风格模型](https://scdn.qpipi.com/2023/06/d827153b4820240403233410.webp)
作为优化模型,与基础模型相比,它的质量较低。但是,它的速度要快得多,非常适合视频和实时应用程序。
此模型的用途
- 训练角色 loras,其中数据集主要由动漫屏幕截图组成,允许更少的动漫风格转移和更少的过度拟合。
- 如果 lora “weak”并且没有提供足够的平面着色,请使用动漫风格.
![图片[4]_AAM AnyLoRA Anime Mix AI绘图模型,动漫屏幕截图风格模型](https://scdn.qpipi.com/2023/06/5275a9de5b141633.webp)
![图片[5]_AAM AnyLoRA Anime Mix AI绘图模型,动漫屏幕截图风格模型](https://scdn.qpipi.com/2023/06/bc24822c51141623.webp)
![图片[6]_AAM AnyLoRA Anime Mix AI绘图模型,动漫屏幕截图风格模型](https://scdn.qpipi.com/2023/06/e554fc720c141620.webp)
建议的设置
- 将 ETA 噪声种子增量 (ENSD) 设置为 31337
- 将剪辑跳到 2
- 禁用人脸恢复。太可怕了,永远不要用
- 使用不会破坏样式的负面提示和嵌入
- 使用动漫视频或Foolhardy作为升频器。如果你知道该怎么做,Latent 会产生一个有趣的效果(参见第一个示例和 Miku 示例)
- (可选以重现某些结果)设置“不要使 DPM++ SDE 在不同批大小之间具有确定性”。
(这个设置实际上并不好,所以我要禁用它,但可能是某些结果不同的原因)
Suggested settings
- Set the ETA Noise Seed Delta (ENSD) to 31337
- Set CLIP Skip to 2
- DISABLE face restore. It’s terrible, never use it
- Use negative prompts and embeddings that don’t ruin the style
- Use AnimeVideo or Foolhardy as upscalers. If you know what to do, Latent makes an interesting effect (see the first example and the Miku one)
- (optional to reproduce some results) Set “Do not make DPM++ SDE deterministic across different batch sizes.”
(this setting is not actually good, so I’m gonna disable it, but might be the reason some results are different)
简史
在Discord上聊天时,我注意到我的Mushoku Tensei风格的LoRA,虽然在AnyLoRA上训练,但在CyberAlchemist的AnimeMix基础模型上表现得更好一些。我在他的HF上读到,这个模型是AnythingElse,他的AnimeMix lora和其他各种风格loras的超级融合。由于 AnimeMix 已经包括了许多我的旧动漫风格 loras,我想尝试制作一个模型,可以最大化我的 Mushoku Tensei 风格的效果,超越 AnyLoRA 和 AnimeMix 所能做到的。
在测试了许多不同的版本、调整设置并从 Discord 频道收到反馈后,我最终得到了一个在 AnyLoRA(基础)上训练的动漫 loras 上运行良好的版本。尤其是我的Mushoku Tensei,在AnyLoRA上感觉非常虚弱。
我不建议将其用于动漫风格的训练(限制在 AnyLoRA 或 NAI 上训练后生成),但它实际上可能相当适合角色 loras,因为您的数据集主要由动漫屏幕盖组成。从技术上讲,它应该减少动漫风格的影响,使角色 lora 不那么过度拟合。我一定会在接下来的几周内尝试一下。
⭐ 如果你创作出了好作品,欢迎分享它。如果您觉得不错请给我一个赞,在社区分享作品吧!期待你的评论!
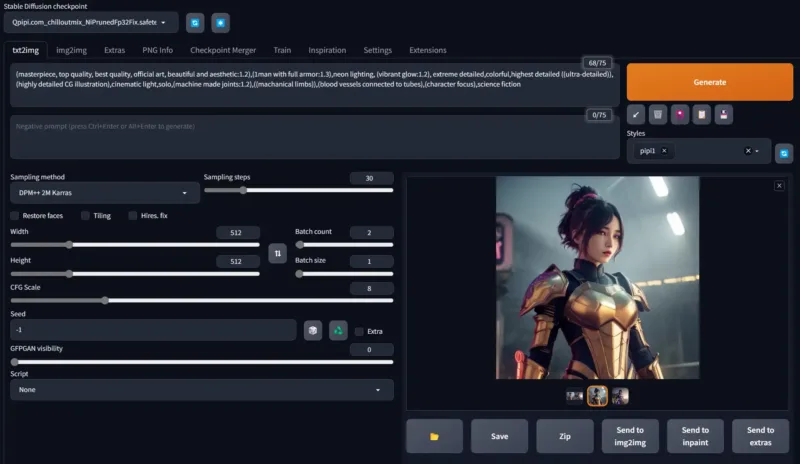
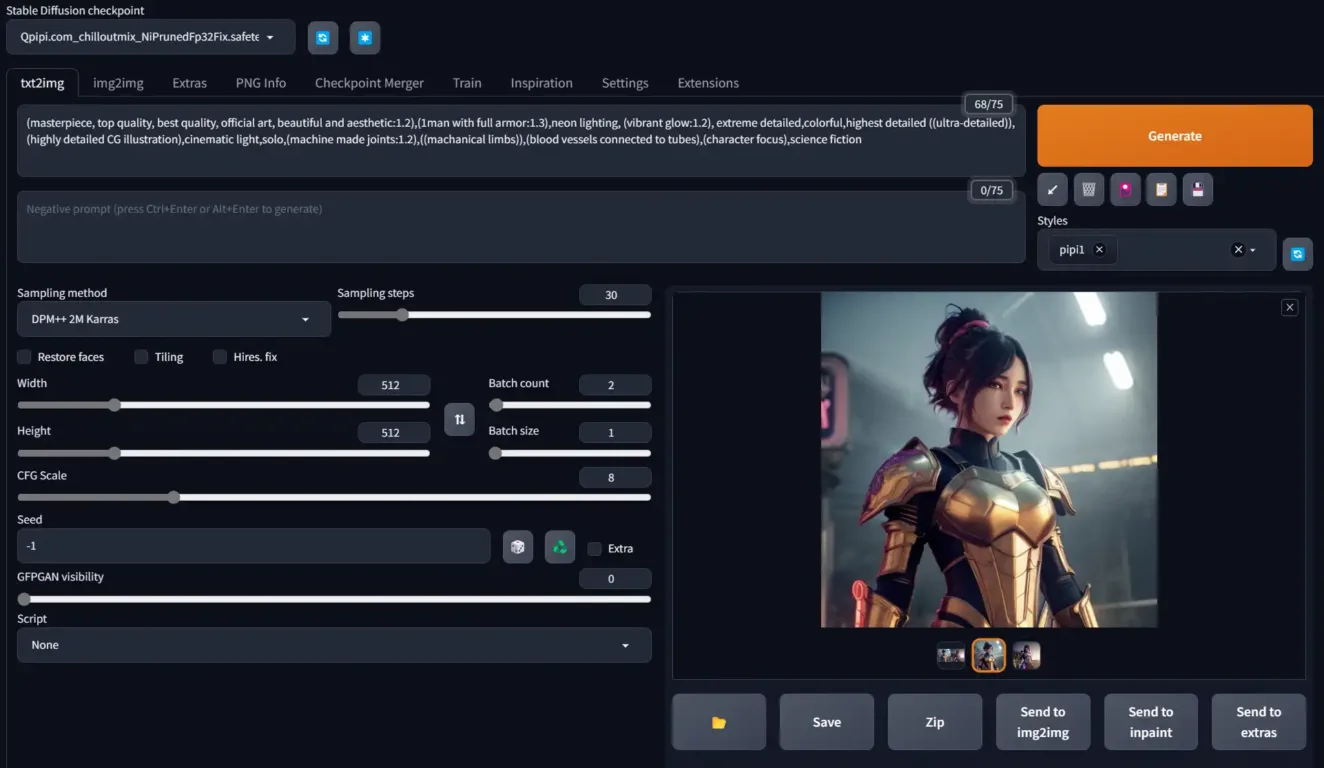
展示图使用了多个我做的动漫角色Lora,如果要的请评论留言。
作品展示和提示

安装说明

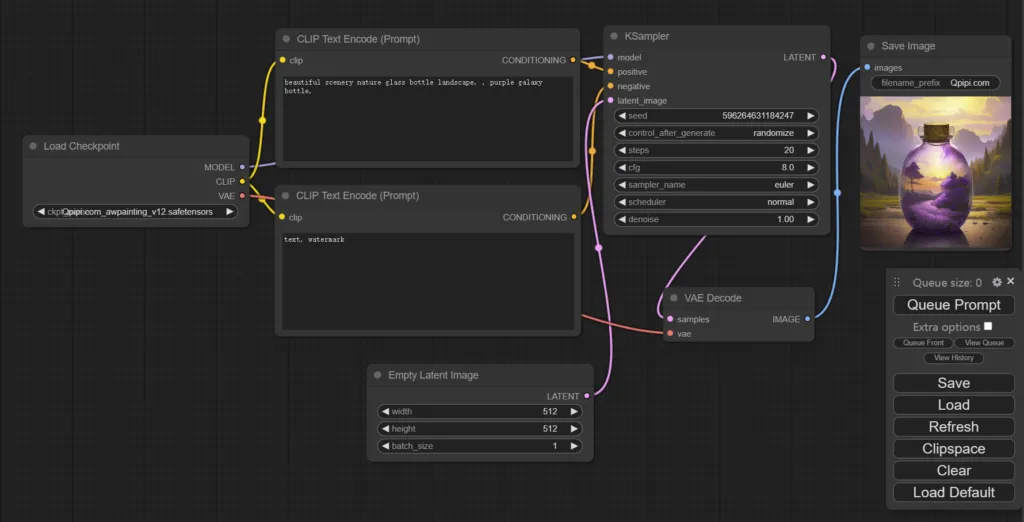
下载SD绘图工具
AI绘图常用工具
希望你喜欢使用这个AI模型,就像我们创造它一样!如果您有任何问题或建议,请在评论区告诉我们。
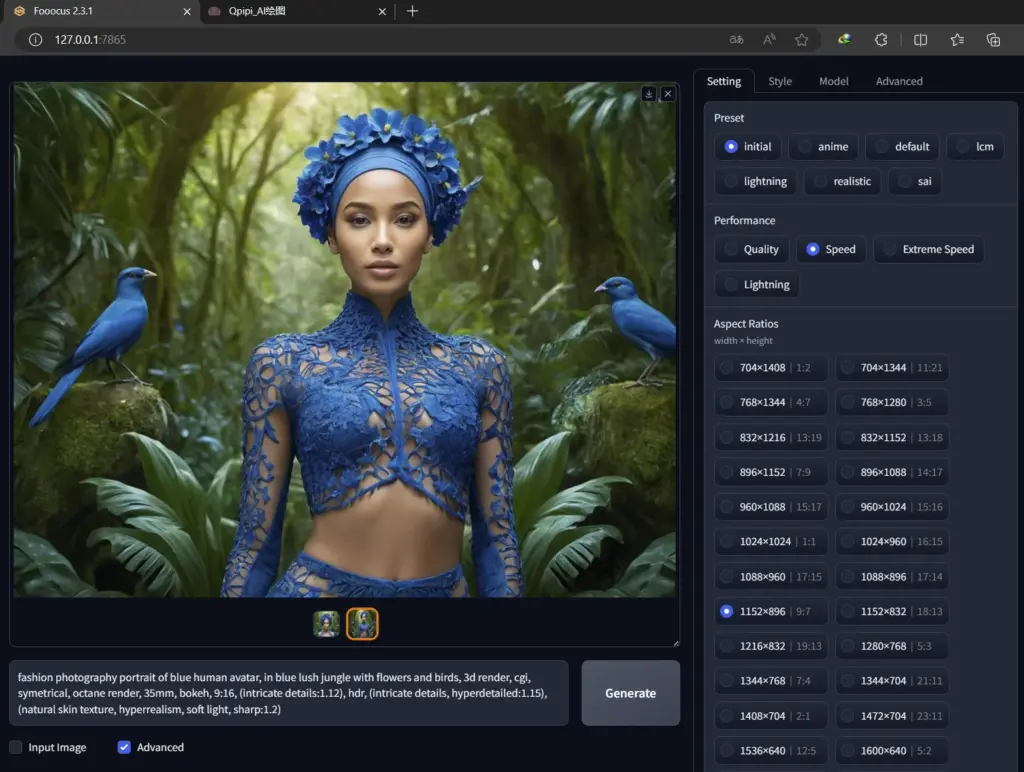
使用Qpipi读图提示功能,获取图片TAG Prompt提示
你想要什么SD绘画模型?请在Qpipi社区或者评论留言告诉我们!
🎨享受精美的AI绘图乐趣!































暂无评论内容