


Hassaku 的目标是成为具有明亮,清晰动漫风格的模特。模型焦点是 nsfw 图像,但也高度强调好看的 sfw 图像。
关于这些事情的小更新:
- 稍微好一点的手牌中档(从坏手到稍微好一点的坏手……在某些图像上,它会有所帮助)
- 对及时的反应更好,提示在嘴里的可能性更高
- 衣服或身体(如翅膀)的细节不太可能与身体分离,左右更平等
- 减少多余的四肢、耳朵、动物耳朵、翅膀
- 似乎衣服上的细节不那么随意
- 构造稍好的背景
难以确定:
- 腰部似乎更粗犷,不确定
更糟糕的是:
- 在某些提示下,衣服会因到处都是“绳子”或洞
而丢失更多请注意,这些点在 clip2 上的许多图像上进行了测试,在某些图像上,这些点可能没有任何作用,甚至比以前更糟。如果大多数训练材料看起来不像我的模型本身生成的图像,则很难通过训练来更新内容。需要来回合并,以便模型本身的外观和行为与训练前一样。正因为如此,它在训练中的变化较小。模型在 150 张图像上进行了训练,后来又与 hassaku 和一些 koji 合并回来。存档的稳定性更高,增加了差异(在较低的分辨率下)。
我以前的模型和我更新的更面向 sfw 的模型。希望你喜欢,请给我一个赞~
![图片[1]_Hassaku AI绘图模型,明亮清晰的动漫风格](https://scdn.qpipi.com/2023/05/7e01b22343140834.webp)
![图片[2]_Hassaku AI绘图模型,明亮清晰的动漫风格](https://scdn.qpipi.com/2023/05/51e01adef1140846.webp)
![图片[3]_Hassaku AI绘图模型,明亮清晰的动漫风格](https://scdn.qpipi.com/2023/05/55e59136cb140852.webp)
![图片[4]_Hassaku AI绘图模型,明亮清晰的动漫风格](https://scdn.qpipi.com/2023/05/e9dfafc80f140832.webp)
![图片[5]_Hassaku AI绘图模型,明亮清晰的动漫风格](https://scdn.qpipi.com/2023/05/8bf172cd92142751.webp)
![图片[6]_Hassaku AI绘图模型,明亮清晰的动漫风格](https://scdn.qpipi.com/2023/05/bfc18b34aa142749.webp)
![图片[7]_Hassaku AI绘图模型,明亮清晰的动漫风格](https://scdn.qpipi.com/2023/05/bcf9fbcf2b142757.webp)
![图片[8]_Hassaku AI绘图模型,明亮清晰的动漫风格](https://scdn.qpipi.com/2023/05/d7b95a2023140847.webp)
使用该模型:
主要使用 danbooru标签。无需额外的 VA。为了更好地使用它,请使用此链接。但是,使用(),而不是{},使用stable-diffusion-webui use()。正面使用“masterpiece”和“best quality”, “worst quality” and “low quality” in negative。
我的负面提示是:(low quality, worst quality:1.4) 在需要时带有额外的单色,签名,文本或徽标。
使用剪辑clip skip1 或 2。clip skip 2 更适合、img2img 和提示跟随。clip skip 1 在视觉上更好,因为我认为模型在那里有更多的时间和自由。我使用剪辑2。
不要使用面部恢复和下划线_,输入 red eyes 而不是red_eyes。
不要使用非常高的分辨率。每个模特,如 hassaku,都会迷失在浩瀚的大图像中。
_____________________________________________________
Loras:
Every LoRA that is build to function on anyV3 or orangeMixes, works on hassaku too. Some can be found here, here or on civit by lottalewds, Trauter, Your_computer, ekune or lykon.
_____________________________________________________
hassaku的基本模型:AnythingV3,ElysiumV2,AbyssOrangeMix,一点AbyssOrangeMix2,basilMix。
黑色结果修复(Web UI 中的 vae 错误):在命令行参数中使用 –no-half-vae
我使用 I use a Eta noise seed delta of 31337 or 0, with a clip skip of 2 for the example images. Model quality mostly proved with sampler DDIM and DPM++ SDE Karras. I love DDIM the most (because it is the fastest).
⭐ 如果你创作出了好作品,欢迎分享它。如果您觉得不错请给我一个赞,在社区分享作品吧!期待你的评论!
安装方法

作品展示和提示指令


SD绘图程序下载
AI绘图常用工具
希望你喜欢使用这个AI模型,就像我们创造它一样!如果您有任何问题或建议,请在评论区告诉我们。
使用Qpipi读图提示功能,获取图片TAG Prompt提示
你想要什么SD绘画模型?请在Qpipi社区或者评论留言告诉我们!
🎨享受精美的AI绘图乐趣!











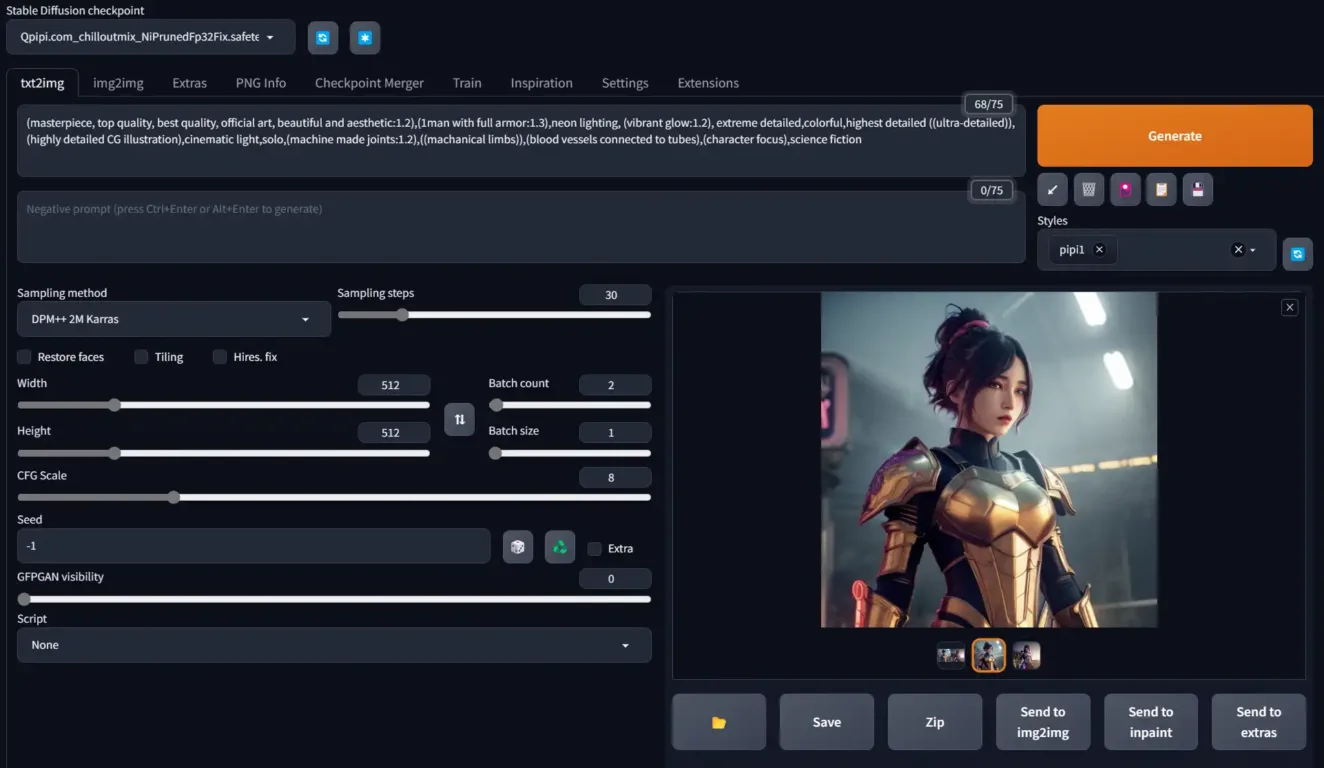
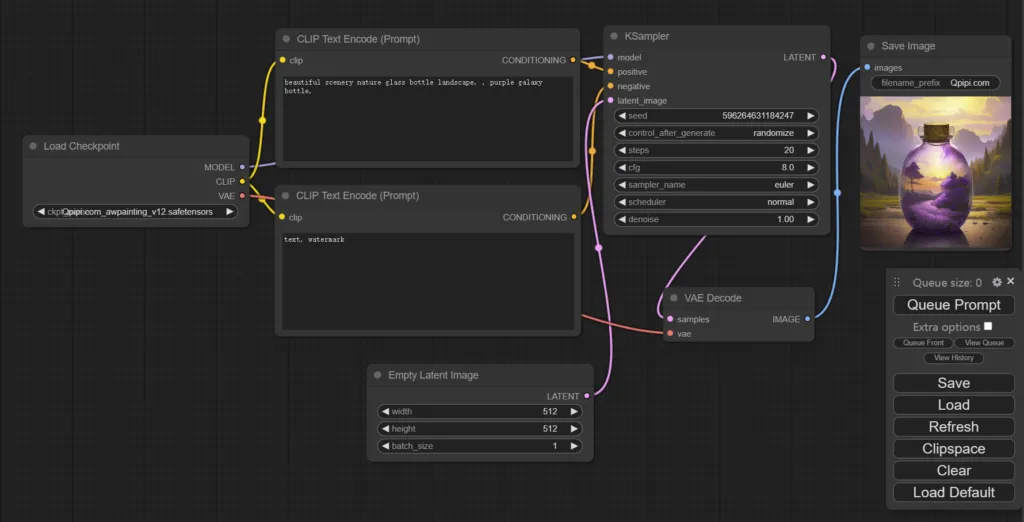
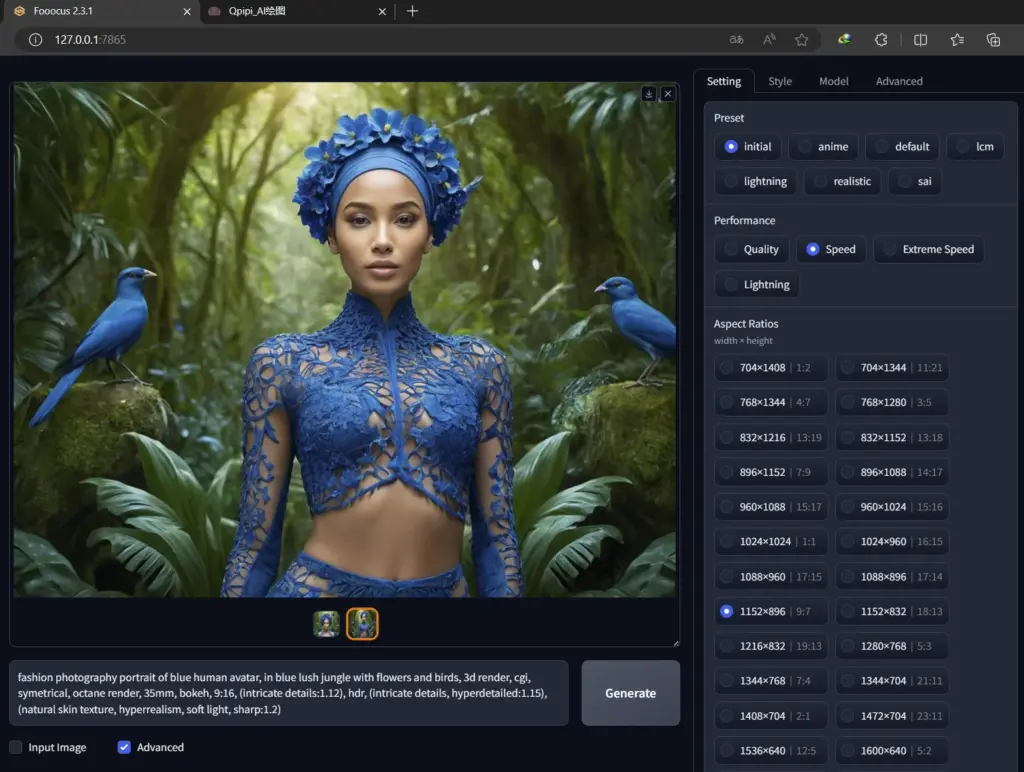
















- 最新
- 最热
只看作者