
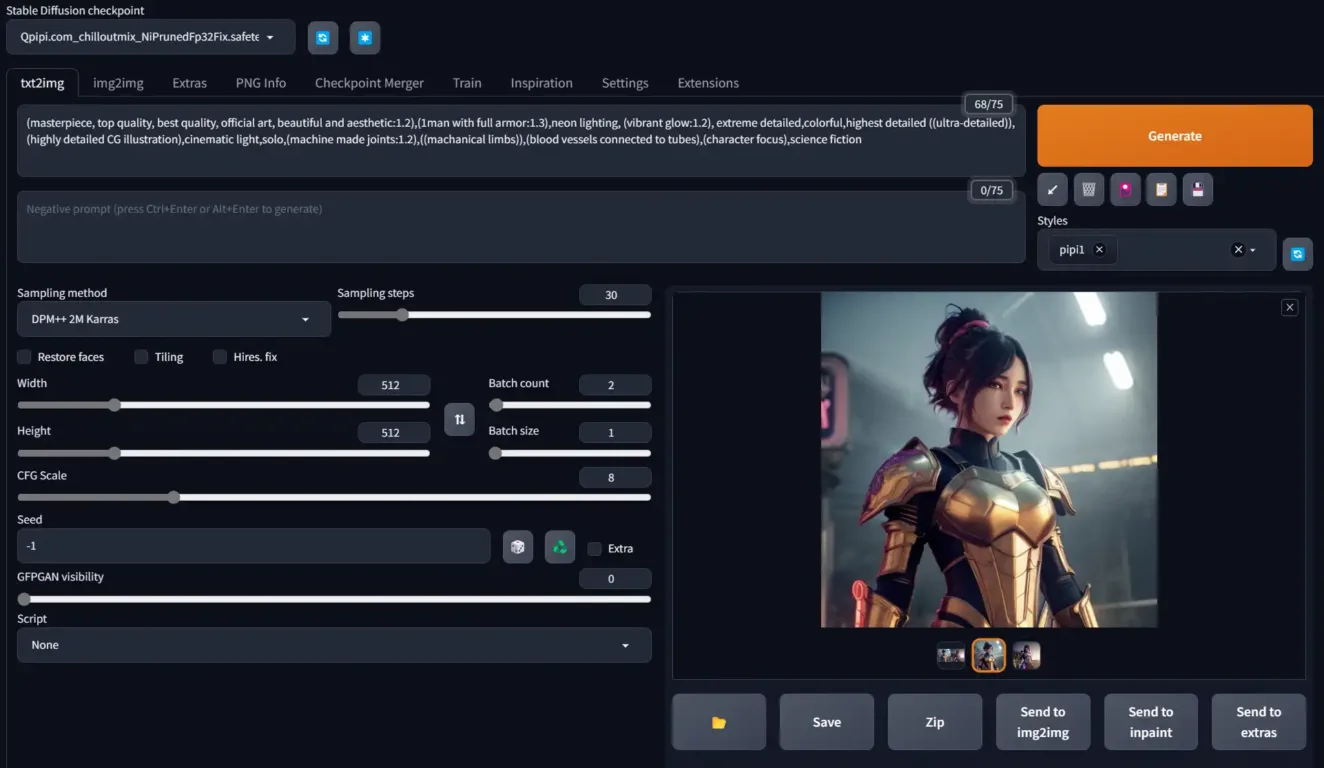
AnySomniumXL成具有自然语言的 2D 样式,并且可能不会生成 SDXL Base 中固有的逼真样式。
该模型使用来自各种来源的数十万张图像的 133,000+ 张精选图像进行训练。该数据集是通过保存美学分数至少为 17 分且最高为 50 分的图像来构建的(以保持卡通模型并且不太逼真。该量表基于我们专有的美学评分机制),并且没有签名或漫画/漫画图像等文本和水印。因此,美学分数小于 17 且大于 50 的图像将被丢弃,带有水印或文本的图像将被丢弃。
![图片[1]_AnySomniumXL AI绘图模型,具有自然语言的 2D 样式_Qpipi](https://scdn.qpipi.com/2024/05/680db9e3d820240505154825.webp)
![图片[2]_AnySomniumXL AI绘图模型,具有自然语言的 2D 样式_Qpipi](https://scdn.qpipi.com/2024/05/0c965fff7d20240505154826.webp)
![图片[3]_AnySomniumXL AI绘图模型,具有自然语言的 2D 样式_Qpipi](https://scdn.qpipi.com/2024/05/857f44538e20240505154827.webp)
![图片[4]_AnySomniumXL AI绘图模型,具有自然语言的 2D 样式_Qpipi](https://scdn.qpipi.com/2024/05/2ad352550720240505154828.webp)
![图片[5]_AnySomniumXL AI绘图模型,具有自然语言的 2D 样式_Qpipi](https://scdn.qpipi.com/2024/05/808db18d3620240505154829.webp)
![图片[6]_AnySomniumXL AI绘图模型,具有自然语言的 2D 样式_Qpipi](https://scdn.qpipi.com/2024/05/2d80c9567120240505154830.webp)
AnySomniumXL v3 技术规格:
- 每 1 个 Epoch 16 个 Epoch 的训练(使用 Epoch 16 的 AnySomniumXL 的结果)
- 由专有的多模态 LLM 提供标题,优于 LLaVA
- 使用 1280×1280 的存储桶大小进行训练
- 随机播放标题:是
- 剪辑跳过:2
- 使用 2 个 NVIDIA A100 80GB 进行训练
创建此数据集的技术结合了 christophschuhmann 的 CLIP 模型和 MLP 评分方法,并进行了我们修改,利用 VIT-L/14 以 -1-100 的等级生成美学评分,并添加了我们的水印检测功能。
成就:
✓ 默认情况下,使用自然语言生成更多 2D 模型,而无需过多的负面或正面提示
✓ 最有可能产生比平均稳定扩散模型更好的手指,无需细节或修复
✓ 生成更真实的 2D 模型,无需负面提示
✓ 不会产生带有随机水印或文字的图像
局限性:
✓ 角色正确握住武器或物品等物体的轻微特征
✓ 仍然需要更广泛的数据集训练
✓ 文本编码器仍有一些空白。还有改进的余地
✓ 无法正确生成文本
✓ 这针对人类或变异人类一代进行了优化。像SCP、小马等非人类可能会产生你所期望的结果
AnySomniumXL v3 Pro 提示:
由于 AnySomniumXL v3 是在 1280×1280 上训练的,因此许多纵横比的分辨率可能与标准 SDXL 模型不同
最佳分辨率(您可以翻转分辨率数字,无论是横向还是纵向):
- 1280×1280
- 1472×1088
- 1152×1408
- 1536×1024
- 1856×832
- 1024×1600
更多版本将提供更广泛的数据集和经过训练的文本编码器。我们的目标是为我们的训练生成最庞大的干净数据集。建议在 Automatic1111 webui 上使用此模型。
AI绘图常用工具
希望你喜欢使用这个AI模型,就像我们创造它一样!如果您有任何问题或建议,请在评论区告诉我们。
使用Qpipi读图提示功能,获取图片TAG Prompt提示
你想要什么SD绘画模型?请在Qpipi社区或者评论留言告诉我们!
🎨享受精美的AI绘图乐趣!


























暂无评论内容