


Animagine XL是一种高分辨率,潜在的文本到图像扩散模型。该模型已使用超过 27000 个全局步骤的学习率进行了微调,批量大小为 16,在优质动漫风格图像的精选数据集上。该模型源自 SDXL 1.0。
推荐搭配VAE:

Animagine XL 3.1 是 Animagine XL V3 系列的更新,增强了之前的版本 Animagine XL 3.0。这种开源的、以动漫为主题的文本到图像模型已经过改进,可以生成更高质量的动漫风格图像。
它包括来自知名动漫系列的更广泛的角色、优化的数据集和新的美学标签,以更好地创建图像。Animagine XL 3.1 建立在 Stable Diffusion XL 之上,旨在通过生成准确而详细的动漫角色表示,成为动漫迷、艺术家和内容创作者的宝贵资源。
Animagine XL 3.0 是复杂的开源动漫文本到图像模型的最新版本,建立在其前身 Animagine XL 2.0 的功能之上。该迭代基于 Stable Diffusion XL 开发,拥有卓越的图像生成能力,在手部解剖学、高效标签排序和增强的动漫概念知识方面进行了显着改进。与之前的迭代不同,我们专注于让模型学习概念而不是美学。
Animagine XL 3.0 在具有 80GB 内存的 2 个 A100 GPU 上进行了 21 天或超过 500 个 GPU 小时的训练。
Animagine XL 3.0 Base 是复杂的动漫文本到图像模型 Animagine XL 3.0 的基础版本。该基础版本包含模型开发的最初两个阶段,重点是建立核心功能和完善关键方面。它为 Animagine XL 3.0 中实现的全部功能奠定了基础。作为更广泛的 Animagine XL 3.0 项目的一部分,它采用了植根于迁移学习的两阶段开发过程。这种方法有效地解决了第一阶段培训结束后UNet中的问题,例如解剖结构断裂。
但是,不建议将此模型用于推理。建议将此模型用作构建的基础。
与其他动漫风格的稳定扩散模型一样,它也支持 Danbooru 标签来生成图像。
![图片[1]_Animagine XL AI绘图模型,SDXL动漫风格大模型](https://scdn.qpipi.com/2023/09/34dba0290b193040-796x1024.webp)
![图片[2]_Animagine XL AI绘图模型,SDXL动漫风格大模型](https://scdn.qpipi.com/2023/09/3df04bcf33193009-720x1024.webp)
![图片[3]_Animagine XL AI绘图模型,SDXL动漫风格大模型](https://scdn.qpipi.com/2023/09/c2f3edda80192950-816x1024.webp)
使用方法:
- 建议在下载模型之前设置 ComfyUI。
- 您需要使用Danbooru风格的标签作为提示而不是自然语言,否则您将获得逼真的结果而不是动漫
- 您可以使用任何通用的负面提示或使用以下建议的负面提示来引导模型走向高审美世代:
lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
- 并且,还应在提示之前附加以下内容,以获得较高的美学效果:
masterpiece, best quality
- 使用此备忘单查找最佳分辨率:
768 x 1344: Vertical (9:16)
915 x 1144: Portrait (4:5)
1024 x 1024: Square (1:1)
1182 x 886: Photo (4:3)
1254 x 836: Landscape (3:2)
1365 x 768: Widescreen (16:9)
1564 x 670: Cinematic (21:9)
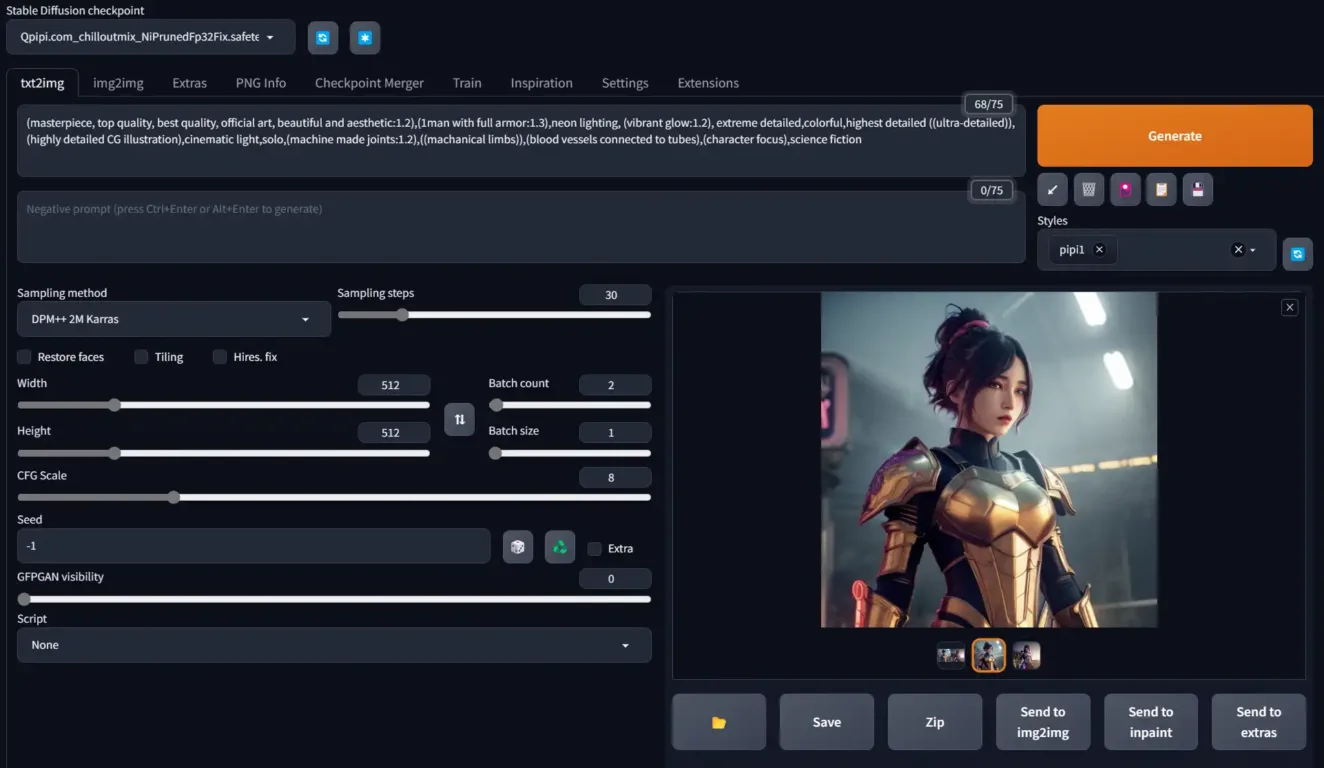
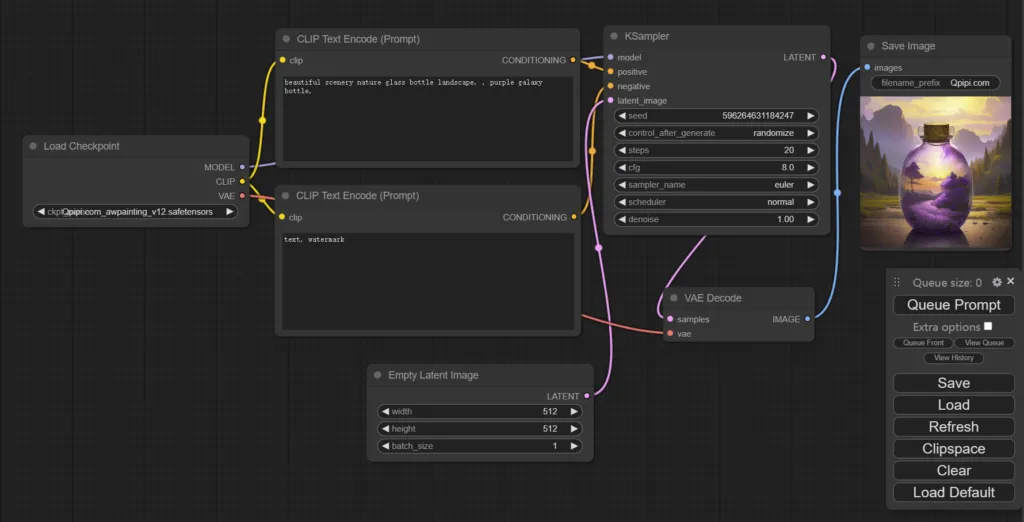
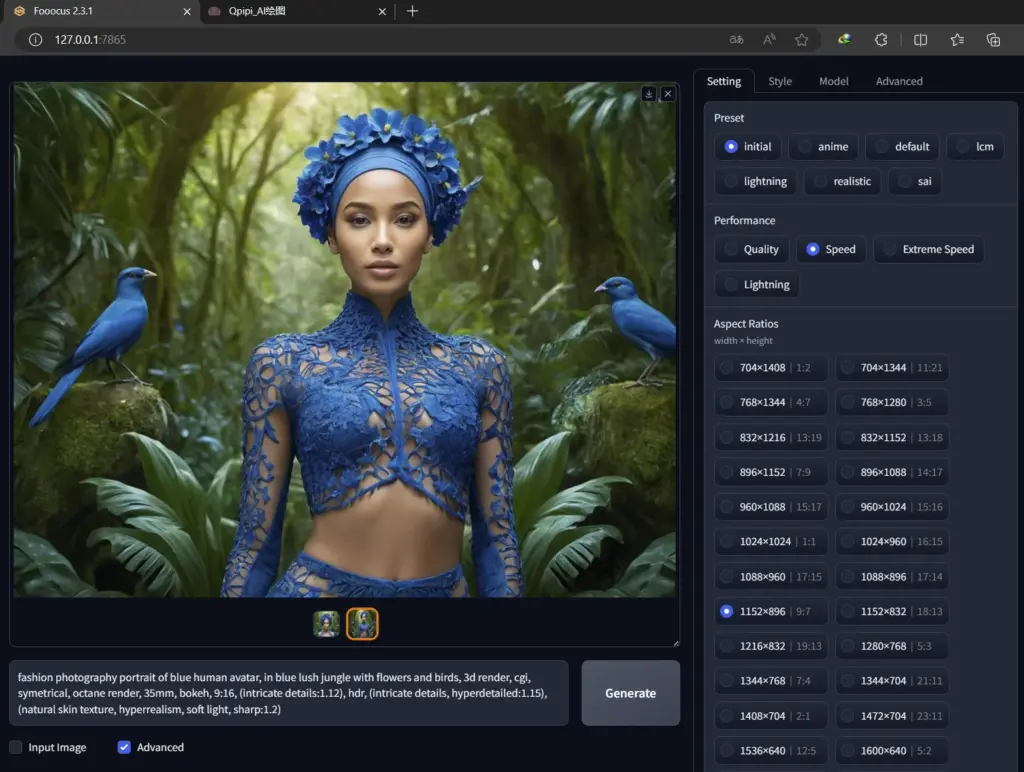
作品展示


AI绘图常用工具
希望你喜欢使用这个AI模型,就像我们创造它一样!如果您有任何问题或建议,请在评论区告诉我们。
使用Qpipi读图提示功能,获取图片TAG Prompt提示
你想要什么SD绘画模型?请在Qpipi社区或者评论留言告诉我们!
🎨享受精美的AI绘图乐趣!





















暂无评论内容