

该模型系列应该是 SDXL 的 ZavyMix SD1.5 模型的延续。主要重点是在风格和独特性上获得与模型相似的感觉,它擅长将魔术与现实主义融合在一起,真正将它们无缝地融合在一起。
当然,随着向 SDXL 的演变,该模型在很多方面(包括眼睛和牙齿)的质量和连贯性应该比 SD1.5 模型更好。这种模式不需要使用精炼器就能获得很好的效果,事实上通常最好不使用精炼器。建议使用终极SD升频器以获得最惊人的效果。
![图片[1]_ZavyChromaXL AI绘图模型,将魔术与现实主义融合](https://scdn.qpipi.com/2024/03/e9adaa483120240404112036.webp)
![图片[2]_ZavyChromaXL AI绘图模型,将魔术与现实主义融合](https://scdn.qpipi.com/2024/03/d1261b6f1b20240404112037.webp)
![图片[3]_ZavyChromaXL AI绘图模型,将魔术与现实主义融合](https://scdn.qpipi.com/2024/03/c791a7308820240404112037.webp)
![图片[4]_ZavyChromaXL AI绘图模型,将魔术与现实主义融合](https://scdn.qpipi.com/2024/03/c766572dfa20240404112038.webp)
![图片[5]_ZavyChromaXL AI绘图模型,将魔术与现实主义融合](https://scdn.qpipi.com/2024/03/3e46189d3320240404112039.webp)
![图片[6]_ZavyChromaXL AI绘图模型,将魔术与现实主义融合](https://scdn.qpipi.com/2024/03/c9dc0321a420240404112040.webp)
关于v6版更新
- 我已经调整了 v5 中的柔和度以增强图像清晰度,尽管我承认这对于某些偏好来说可能太过倾斜了。我的目标是在几周内发布 v6.1,在 v5 的柔和音调和 v6 的锐利演绎之间取得平衡。这将提供两全其美的效果。同时,如果您更喜欢 v5 的柔和焦点,请随时继续使用它。对于那些寻求更清晰图像的人来说,对汽车等主题特别有用,v6 可能是您的首选。
- 增加(上)牙齿训练、布料纹理、皮肤纹理、景观、整体成分等。
- 与 V5 相比,某些提示的结果可能会感觉非常不稳定,当恢复 V5 的某些部分时,这种情况会得到缓解。
![图片[7]_ZavyChromaXL AI绘图模型,将魔术与现实主义融合](https://scdn.qpipi.com/2024/03/6f57eb92ab20240320143121.webp)
![图片[8]_ZavyChromaXL AI绘图模型,将魔术与现实主义融合](https://scdn.qpipi.com/2024/03/5b460ed23d20240320143126.webp)
![图片[9]_ZavyChromaXL AI绘图模型,将魔术与现实主义融合](https://scdn.qpipi.com/2024/03/d8deff199320240320143124.webp)
考虑将 DPM++ 3M SDE Exponential 用于此模型,我个人最喜欢它适用于各种样式。如果您想创建逼真的图像以及一些示例图像,请务必进一步阅读本节中的提示建议。
优点
- 饱和度比基本模型好得多。
- 牙齿、眼睛、手和脚要好得多。
- 增加真实感。
- 边缘不那么模糊,但仍然保持图像的某种令人愉悦的柔和度。
- 好看的人。
- 质感和色调都很好。
缺点
- NSFW 比 base 好得多,但没有 LORA 仍然有些欠缺。
技巧
- 为了更好地理解模型的偏好,鼓励个人利用提供的提示作为基础,然后根据他们想要的目标自定义、修改或扩展它们。
- 抛弃精炼器,img2img 终极 SD 升频器在选择此型号时会获得更好的效果。
- 当面部结果低于标准,但图像的其余部分很有趣时,请考虑使用面部恢复技术。
- 如果您发现工作中缺少细节,如果您无法仅通过提示来修复它,请考虑使用 wowifier。wowifier 或类似工具可以增强和丰富细节水平,从而产生更引人注目的输出。
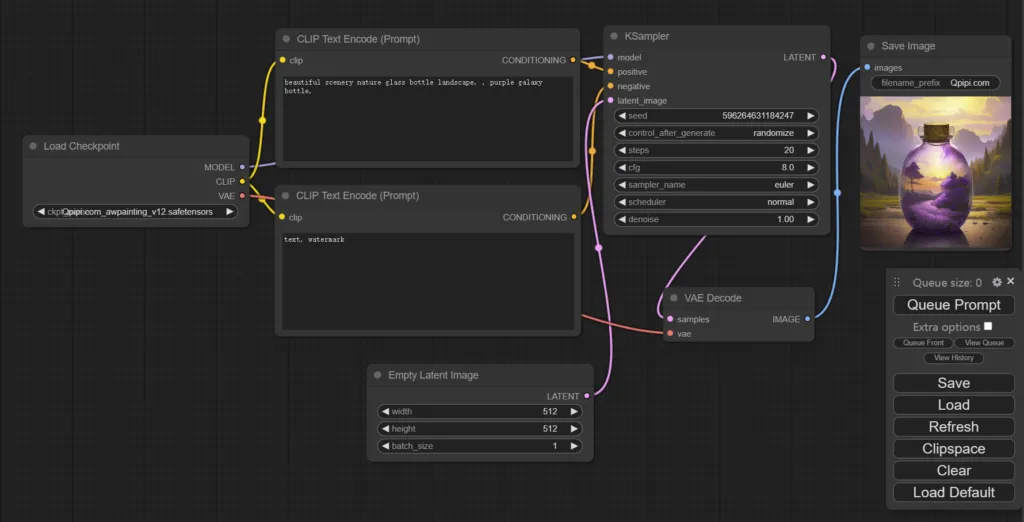
- ComfyUI 是我用于 SDXL 图像的 UI。
- 您的 1.5 LORA 在 SDXL 中不起作用。
- 考虑寻找新的提示,不要使用标准的 1.5 提示。SDXL 喜欢将自然句子与后面添加一些关键字的组合。
- 为了保持最佳效果并避免拍摄对象过度重复,请将生成的图像大小限制为最大 1024×1024 像素或 640×1536(反之亦然)。如果您需要更高的分辨率,建议使用 Hires 修复,然后是 img2img 高档技术,特别强调 controlnet 磁贴高档方法。这种方法将帮助您在追求更高分辨率的输出时获得卓越的结果。但是,由于此工作流尚不适用于 SDXL,因此您可能希望将 SD1.5 模型用于 img2img 步骤。
![图片[10]_ZavyChromaXL AI绘图模型,将魔术与现实主义融合](https://scdn.qpipi.com/2024/03/6b67d6729f20240320143120.webp)
![图片[11]_ZavyChromaXL AI绘图模型,将魔术与现实主义融合](https://scdn.qpipi.com/2024/03/04b307daf820240320143121.webp)
![图片[12]_ZavyChromaXL AI绘图模型,将魔术与现实主义融合](https://scdn.qpipi.com/2024/03/69ee2c57de20240320143114.webp)
Prompts
Recommended positive prompts for specifically photorealism: 2000s vintage RAW photo, photorealistic, film grain, candid camera, color graded cinematic, eye catchlights, atmospheric lighting, macro shot, skin pores, imperfections, natural, shallow dof, or other photography related tokens.
Recommended negative prompts: As few negative prompts as you can, only use it when it does something you do not want, like watermarks.
我们进一步鼓励您提供有关所需输出的其他具体详细信息。这应该包括指定首选风格、相机角度、照明技术、姿势、配色方案和其他相关因素。
Recommended settings
- sdxl_vae.safetensors (baked in).
- DPM++ 3M SDE Exponential, DPM++ 2M SDE Karras, DPM++ 2M Karras, Euler A
- Steps 20~40 (lower range for DPM, higher range for Euler).
- Hires upscaler: UltraMix_Balanced.
- Hires upscale: Whatever maximum your GPU is capable of, but preferably between 1.5x~2x.
- CFG scale 4-10 (preferably somewhere around cfg 6-7)
Lightning LoRA specific settings:
- Euler sampler with SGM Uniform as Scheduler.
- Steps 4 (use the 4 steps LoRA)
- CFG scale 1-2 (CFG 1 at the higher weights for the LoRA)
- LoRA weight 0.6-1
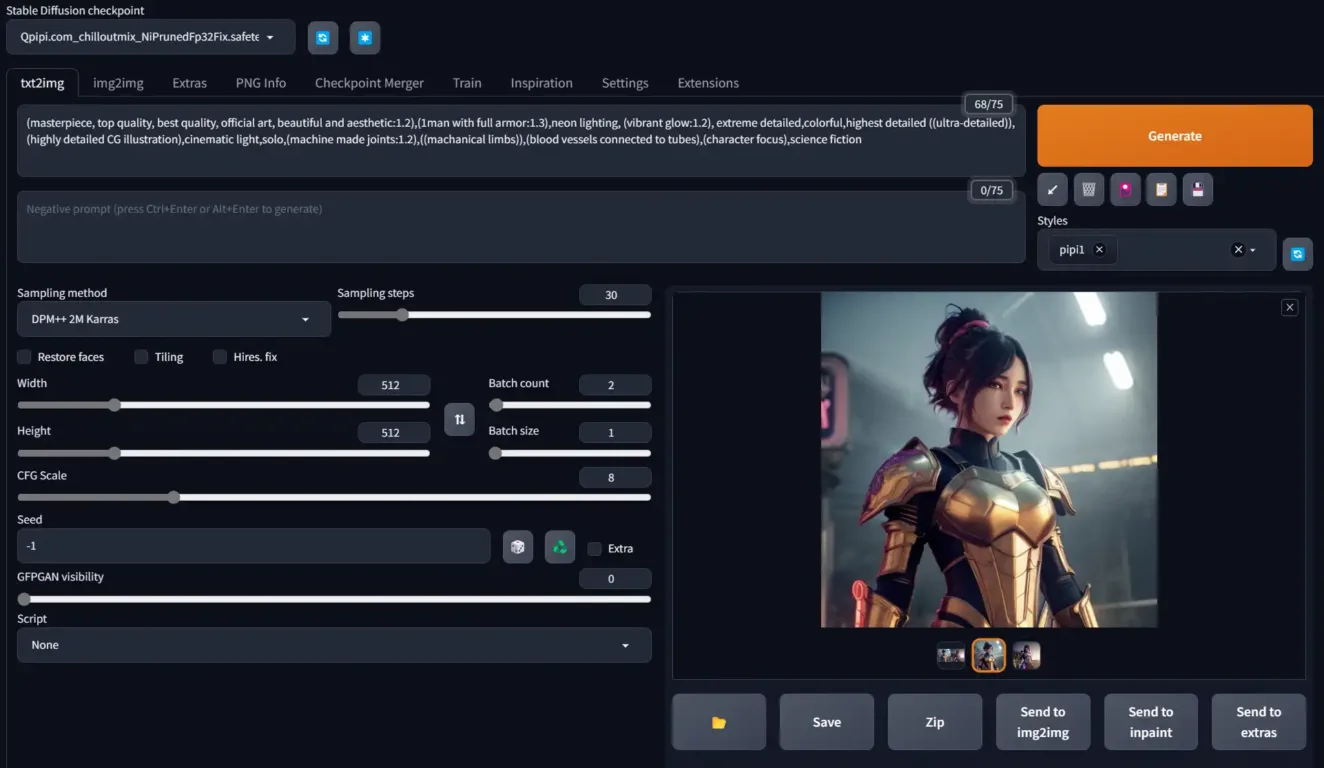
作品展示

AI绘图常用工具
希望你喜欢使用这个AI模型,就像我们创造它一样!如果您有任何问题或建议,请在Qpipi社区分享。
使用Qpipi读图提示功能,获取图片TAG Prompt提示
开箱即用!ComfyUI:强大、模块化的 Stable Diffusion 操作界面和后端
强大的开源AI绘图工具Stable Diffusion Webui最全本地安装指南
Stable Diffusion一键安装懒人包新版,Easy Diffusion支持Windows、Mac绿色安装包
找不到你想要的AI绘画模型下载?请在SD社区或者评论留言告诉我们!
🎨享受精美的AI绘图乐趣!





























暂无评论内容